

CRNN网络调研适配记录
大约 7 分钟
CRNN网络调研适配记录
0.项目
论文配套代码:https://github.com/bgshih/crnn/tree/master
pytorch复现代码:https://github.com/meijieru/crnn.pytorch
1. 网络介绍
1.0 目标
- 同期的DCNN网络需要人工标记字符位置进行识别,需要实现端到端训练
- 能够处理不同长度的输入序列,产生可变长的标签序列
- 基于图像的序列识别(场景文本识别,手写字符识别,乐谱识别)

2024-01-08 11-59-42 的屏幕截图
1.1 数据集
- Synth90k:用于文本识别的生成数据集,包含900万个训练样本,涵盖90k个英语单词并已划分好训练验证测试集,10GB
- 使用 粗体/阴影/灰度/投影变换/融入自然纹理 等多种方式生成图像
- 灰度图

Synthetic Data Engine process - 示例:




1.2 网络结构
由三部分组成:卷积层,循环层和转录层
- 卷积层:提取输入图像特征序列
- 循环层:预测标签分布
- 转录层:将标签分布转为最终输出标签序列
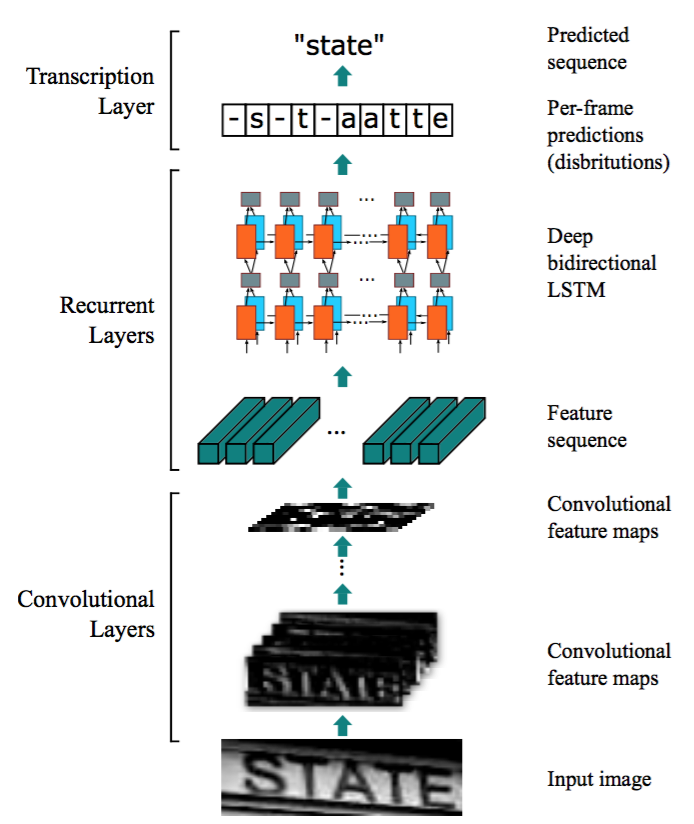
Figure 1 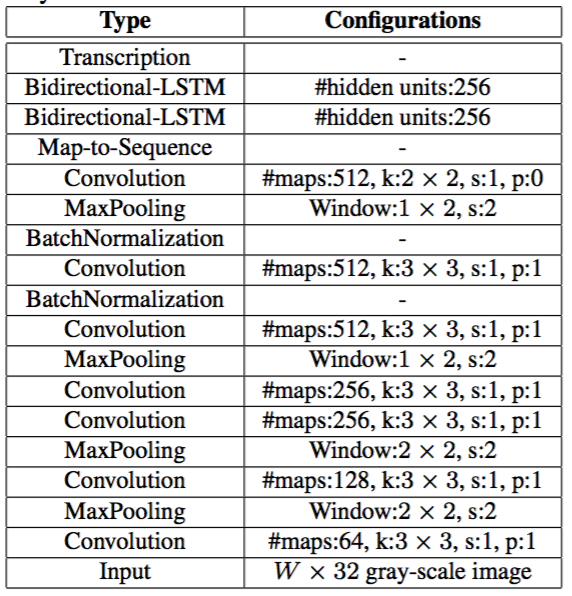
Table 1 CRNN( (cnn): Sequential( (conv0): Conv2d(1, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (relu0): ReLU(inplace=True) (pooling0): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) (conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (relu1): ReLU(inplace=True) (pooling1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) (conv2): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (batchnorm2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu2): ReLU(inplace=True) (conv3): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (relu3): ReLU(inplace=True) (pooling2): MaxPool2d(kernel_size=(2, 2), stride=(2, 1), padding=(0, 1), dilation=1, ceil_mode=False) (conv4): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (batchnorm4): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu4): ReLU(inplace=True) (conv5): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (relu5): ReLU(inplace=True) (pooling3): MaxPool2d(kernel_size=(2, 2), stride=(2, 1), padding=(0, 1), dilation=1, ceil_mode=False) (conv6): Conv2d(512, 512, kernel_size=(2, 2), stride=(1, 1)) (batchnorm6): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu6): ReLU(inplace=True) ) (rnn): Sequential( (0): BidirectionalLSTM( (rnn): LSTM(512, 256, bidirectional=True) (embedding): Linear(in_features=512, out_features=256, bias=True) ) (1): BidirectionalLSTM( (rnn): LSTM(256, 256, bidirectional=True) (embedding): Linear(in_features=512, out_features=37, bias=True) ) ) )
1.2.1 CNN
- 不包含全连接层,模型参数量小
- 使用矩形池化窗口生成更长的特征序列,得到矩形感受野,有助于识别窄的字符(如i,l)
- 特征序列的每列对应于原始图像的一个矩形感受野,可认为是该区域的特征向量。
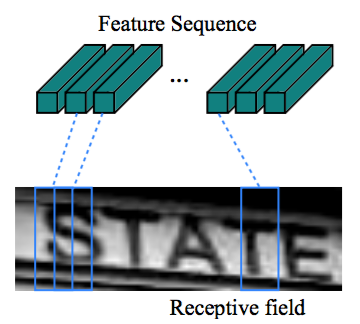
Figure 2
1.2.2 RNN
- 能够捕获序列内上下文信息,对于基于图像的序列识别使用上下文提示比独立处理每个符号更稳定且更有帮助
- 一些模糊的字符在观察其上下文时更容易区分
- RNN可以将误差差值反向传播到其输入,即卷积层,从而允许在统一的网络中共同训练循环层和卷积层
- RNN能够从头到尾对任意长度的序列进行操作
- 使用双向LSTM,将两个LSTM,一个向前和一个向后组合到一个双向LSTM中,并且可进行堆叠
- 基于图像的序列中,两个方向的上下文是相互有用且互补的
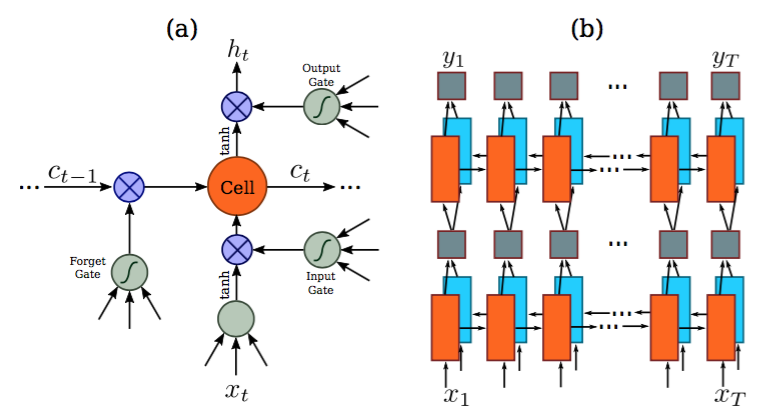
Figure 3
1.2.3 转录层
- RNN输出的概率矩阵每个时间序列取max得到对应字符集中的字符
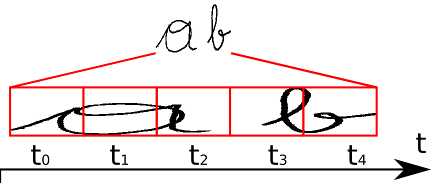
img - aaabb -> ab
- 将输出序列转换为最后识别结果的方法:
- 遇到连续相同的字符则去重合并(存在问题:输出单词存在重复字符的情况 apple -> aple; 空白序列如何表示?)
- 在每个字符前后分别插入空字符,之后再做去重: apple -> -a-p-p-l-e-
- 示例:-a-pp-p--l-ee -> apple
1.2.4 CTC Loss
- 如何定义损失函数来解决图像文本长度不定长的对齐解码问题?
- 在给定时间序列长度T,label L的情况下,预测结果preds通过转录层后能够得到label相同值的搜索路径如下:
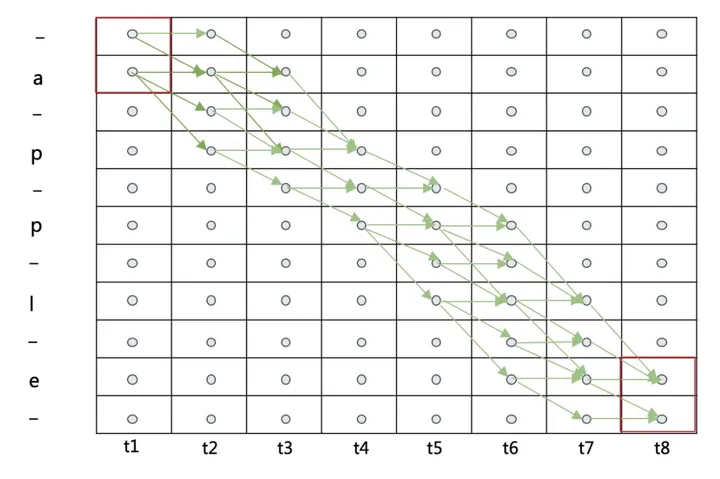
img - 其中一条搜索路径如下图,输出结果为:--ap-ple -> apple
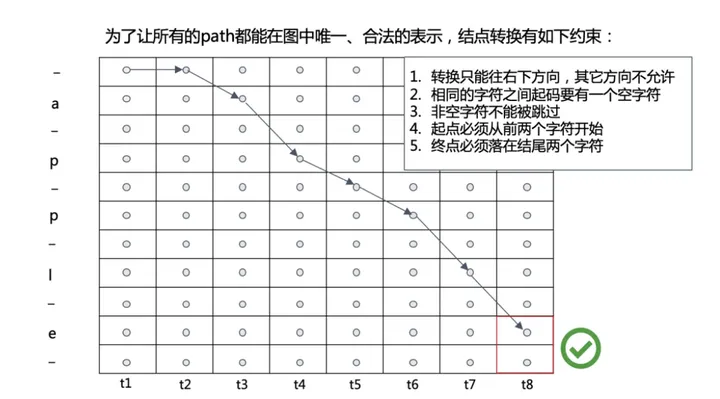
img
- 基本思想:假设CTC输出的原始序列为$Z$,目标文本序列为$Y$,输入CTC的输入序列为$X$,只要找到所有可以转录成标注序列$Y$的原始序列$Z$,计算这每个原始序列$Z$的概率之和,这个概率和就是CTC分支预测为$Y$的概率$P(Y|X)$,我们希望这个概率越大越好,所以我们只需要以最大化这个概率和为目标函数,就可以实现CTC分支的训练,并且回避掉对齐的问题
- 定义:
- $\alpha(s,t)$: 第t个时刻,字符串$l^{'}$的第s个字符的路径前向概率
- $p^t(Z_s|X)$: 预测矩阵中第t时刻是第s个字符的概率
- $p(l|x)$: 输入序列x,输出为l的概率,我们要最大化其概率
- 公式:
- $$\alpha(s,t) = \begin{cases} \alpha(s,t)=(\alpha(s-1,t-1)+\alpha(s,t-1))*p^t(Z_s|X), \quad s=\epsilon \quad or \quad s=s-2, t>0, s>0 \ \alpha(s,t)=(\alpha(s-1,t-1)+\alpha(s,t-1)+\alpha(s-2,t-1))*p^t(Z_s|X), \quad s\neq s-2, t>0, s>0 \end{cases}$$
- $p(l|x)=\alpha(s,t)+\alpha(s+1,t)$
- $argmax(p(l|x))\Rightarrow argmin(-ln(p(l|x)))$
- 使用HMM的forward-backward 算法计算梯度:
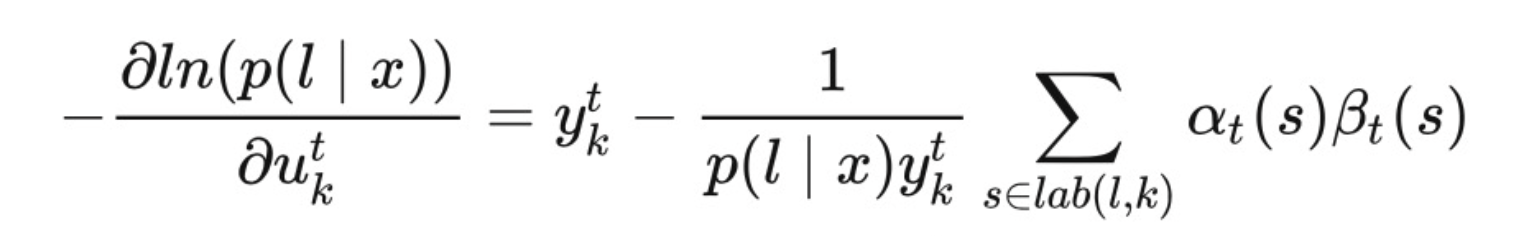
- 可将loss计算转化为两张表的计算:
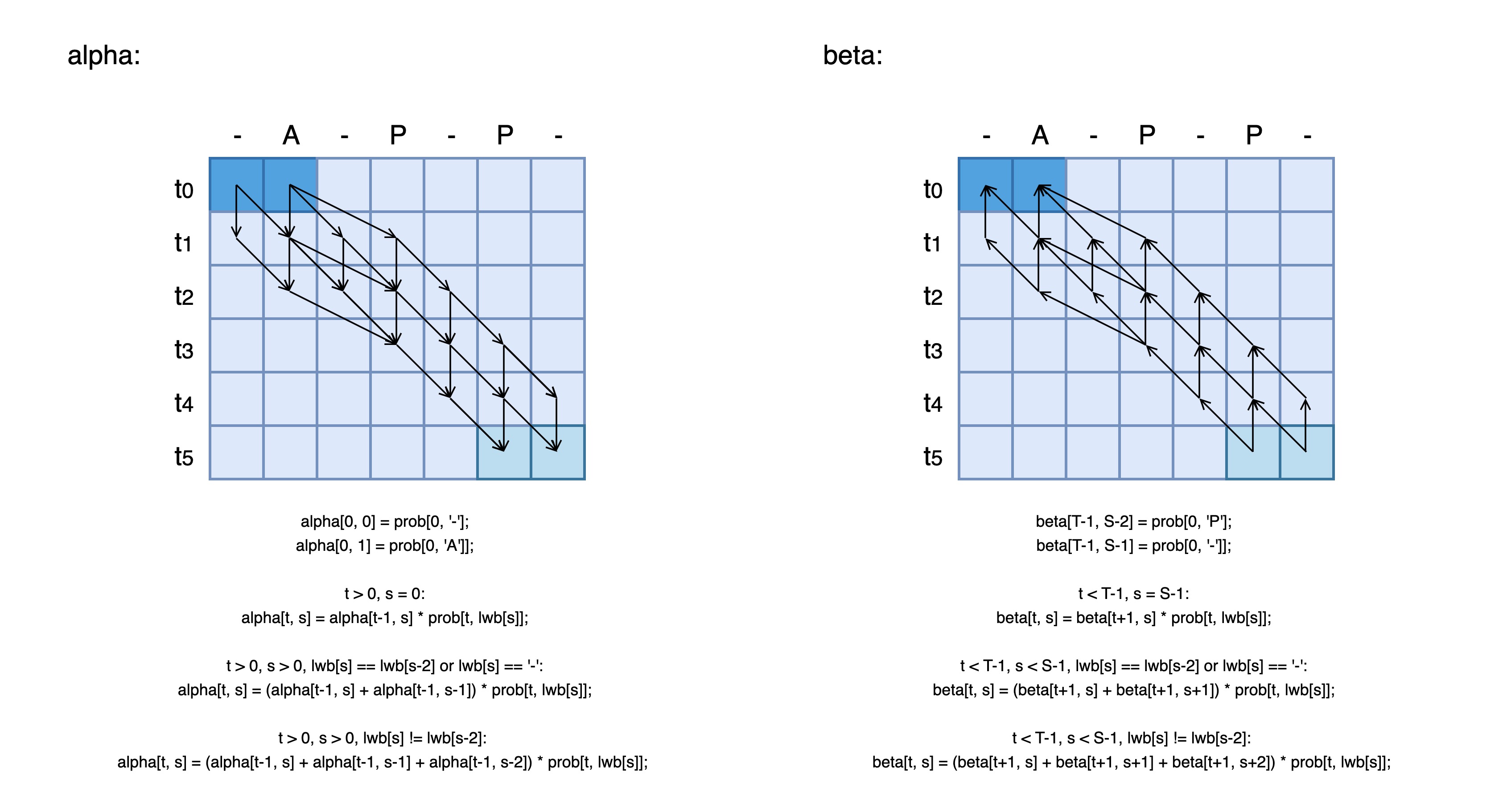
- 各框架实现方案:
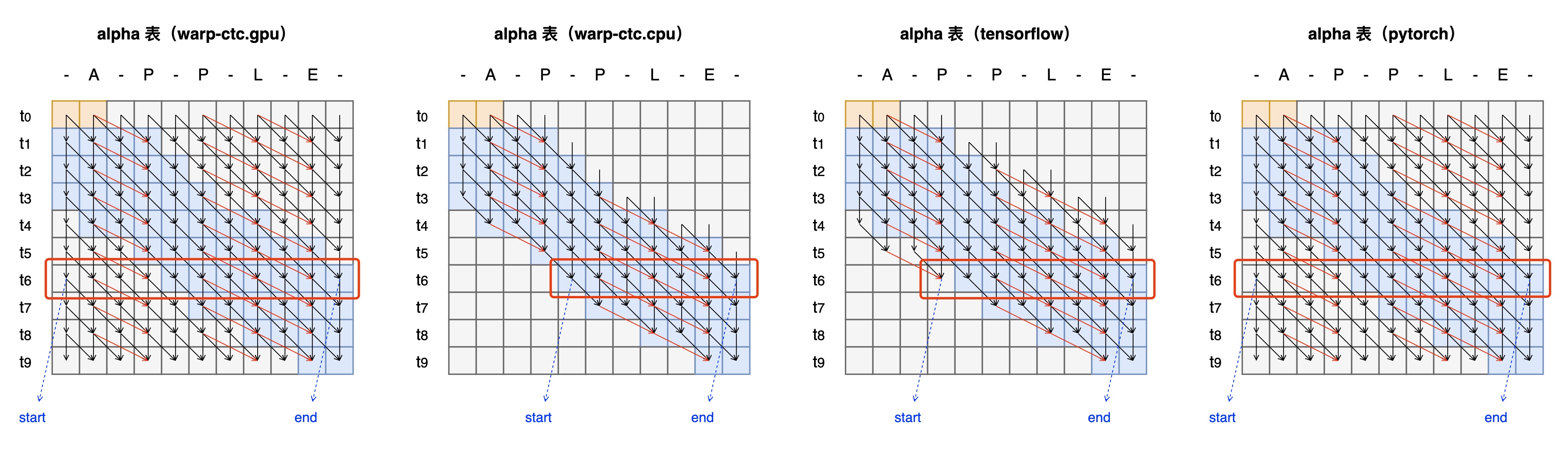
image2023-2-17_2-20-26 - 旧方案:采用warp-ctc.cpu方案,需要将整个probs表加载进nram,不用计算所有路径,计算量小,但除softmax外其它计算为标量计算,效率低
- 新方案:
- 规模受限方案:nram可放下整个probs表,alpha,beta表
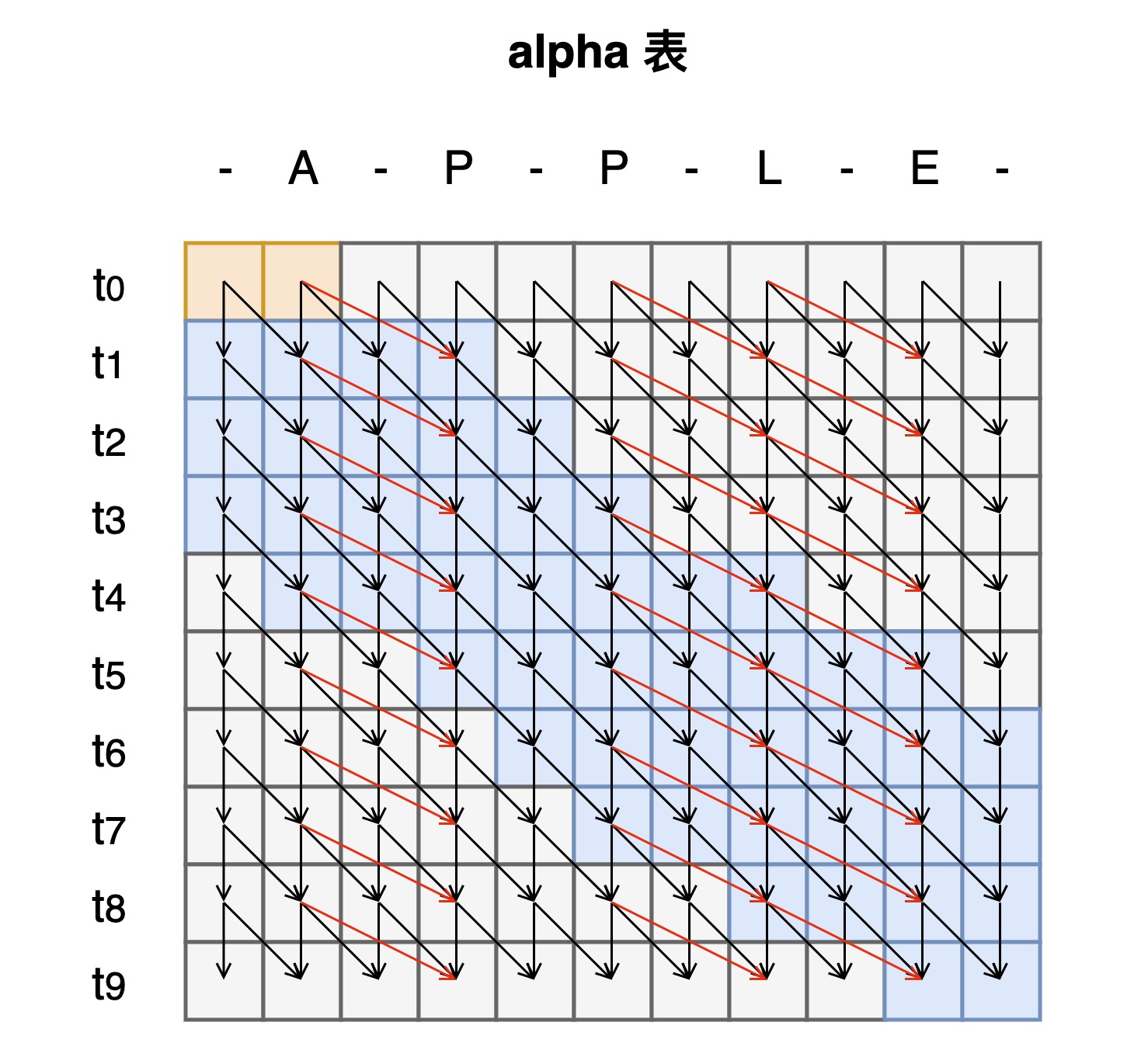
- 沿着t方向计算时,所有线程的计算区间涵盖整个搜索空间,可实现想量化,可将不同的情况下的计算拆分为两步再加上mask得到最后结果
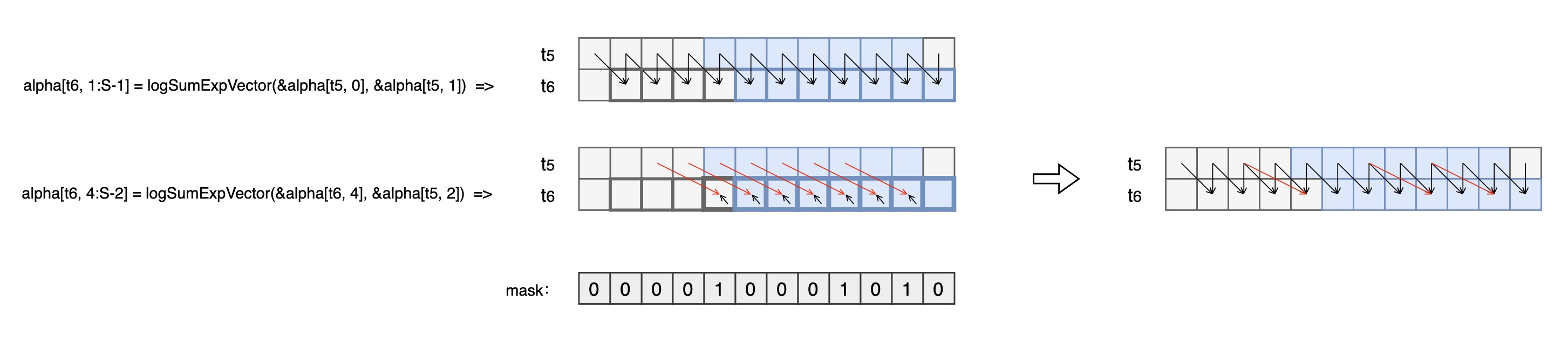
image2023-2-17_3-41-26 
image2023-2-17_3-42-6
- large tensor方案:字符集非常大,nram无法放下整个probs表,alpha,beta表
- 将alpha/beta表分块加载与计算:
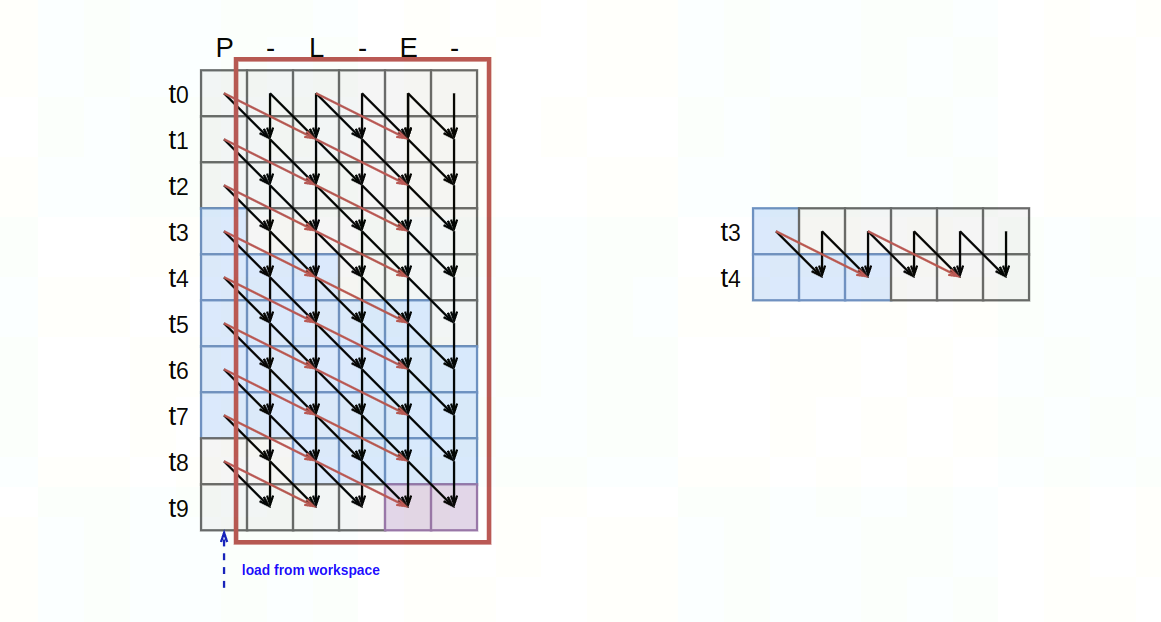
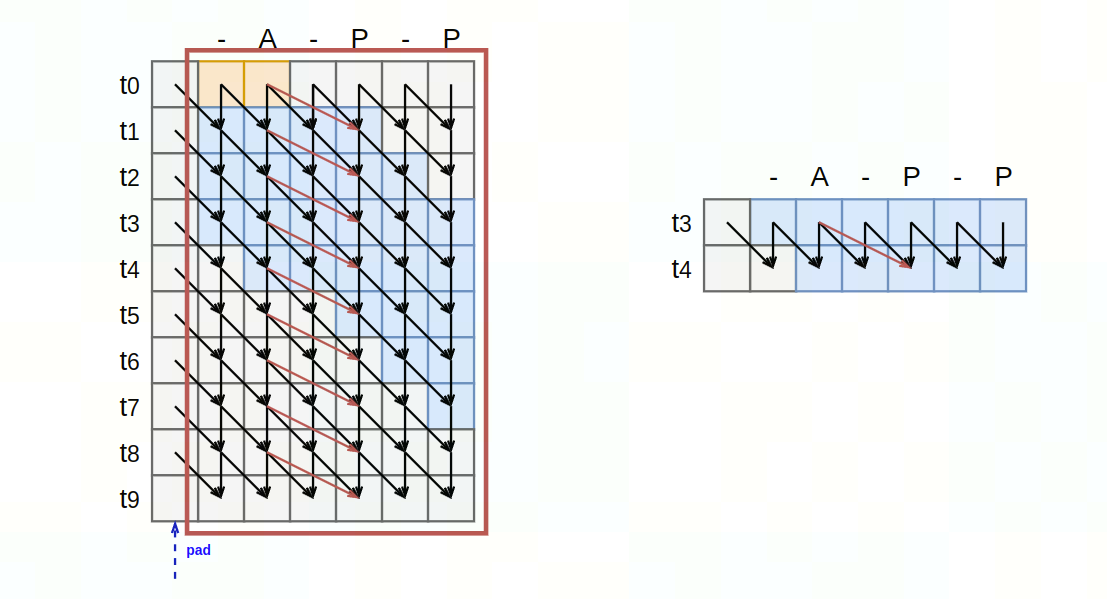
- 规模受限方案:nram可放下整个probs表,alpha,beta表
1.3 训练流程:
输入图像(61,31)(长度不定,高度均为31):

resize(双线性插值)为(100,32):

送入网络中:
preds = model(image) # [T,N,C]=[26,1,37], T: 最长序列长度,N:batchsize,C:字符集大小, 整体表示输出序列在整个字符集上取对应字符的概率处理label:
# alphabet="0123456789abcdefghijklmnopqrstuvwxyz" # len(alphabet) = 36 加上分隔符epsilon(用'-'表示)共37个 # raw_label:'Fermi' # text:tensor([16, 15, 28, 23, 19]), Size[5] # text_length:tensor([5]), Size[1] # encode处理输入label,得到编码后的序列和对应长度 text, text_length = converter.encode(raw_label)计算loss:
# preds: Size[26,1,37] # preds_size: Size[26] # text: Size[5] # text_length: Size[1] loss = CTCLoss(preds, text, preds_size, text_length)更新参数(adam) ...
验证输出内容:
_, preds = preds.max(2) preds = preds.transpose(1, 0).contiguous().view(-1) # preds = tensor([16, 16, 0, 0, 0, 0, 0, 0, 15, 0, 0, 28, 0, 0, 0, 23, 23, 0, 0, 0, 0, 19, 0, 0, 0, 0]) # preds_size: Size[26] converter.decode(preds, preds_size) # ff------e--r---mm----i---- => fermi
2. 适配记录
- 重构训练脚本,统一编码风格,封装功能实现为类与函数
- 替换旧版本API,CTC Loss实现由
warpctc_pytorch替换为pytorch原生torch.nn.CTCLoss - 完善log, checkpoints记录与保存
- 修改训练方式为DDP
- 解决Dataloader和数据加载模块的一些bug
3. 性能精度测试
| 设备 | 卡数 | batchsize/card | throughput (fps) | 扩展率 (%) | e2e time (s) |
|---|---|---|---|---|---|
| V100-PCIE-32G | 单机1卡 | 512 | 2612.24 | 1 | 0.1960 |
| V100-PCIE-32G | 单机8卡 | 512 | 12657.60 | 60.57% | 0.3236 |
4. 参考链接
https://ycc.idv.tw/crnn-ctc.html
https://zhuanlan.zhihu.com/p/43534801
https://zhuanlan.zhihu.com/p/71506131
https://www.cnblogs.com/skyfsm/p/10335717.html
https://distill.pub/2017/ctc/
https://zhuanlan.zhihu.com/p/42719047
https://zhuanlan.zhihu.com/p/285918756