

HugeCTR源码阅读笔记
HugeCTR源码阅读笔记
1. Data
深度推荐模型的输入特征可分为数值特征和分类特征,数值特征是一组连续值,而分类特征是离散值,以HugeCTR按照Criteo点击率数据格式(每个数据sample包括14个数值特征和26个分类特征,总共40个特征)合成的数据为例:
数值特征(numeric feature、dense feature):
_col0 _col1 _col2 _col3 _col4 _col5 _col6 0 0.080380 0.435741 0.078185 0.194161 0.087724 0.845081 0.937019 1 0.310647 0.669963 0.218886 0.945537 0.735421 0.637027 0.007011 2 0.337267 0.908792 0.795987 0.608301 0.290421 0.012273 0.671650 3 0.873908 0.694296 0.796788 0.553089 0.872149 0.502299 0.114150 4 0.333109 0.456773 0.403027 0.091778 0.215718 0.729457 0.941204 _col7 _col8 _col9 _col10 _col11 _col12 _col13 0 0.977882 0.042342 0.054632 0.855919 0.264451 0.224891 0.467242 1 0.204856 0.307856 0.775143 0.265654 0.301945 0.066413 0.499416 2 0.960113 0.018073 0.639101 0.229013 0.645756 0.123180 0.894010 3 0.444433 0.001794 0.147979 0.083302 0.744487 0.971924 0.362019 4 0.997079 0.563684 0.811862 0.457039 0.133213 0.169442 0.124149
分类特征(sparse feature、category feature):
_col14 _col15 _col16 _col17 _col18 _col19 _col20 _col21 _col22 0 151 0 9 13 1 1 1 9 4 1 0 0 11 4801 44 2 160 9 0 2 4549 3 1 10 31 2 485 2 10 3 0 0 1 1 1 0 3 111 10 4 2 5 160 0 72 0 13 53 0 _col23 _col24 _col25 _col26 _col27 _col28 _col29 _col30 _col31 0 2 395 41 1 14 5 2 7 0 1 101 3 1 1 4 1 1 1 1 2 2 19 6 6 1 0 4 1 2 3 1 2 38 6 1 7 1 2 0 4 63 616 7 1 175 23 4 0 1 _col32 _col33 _col34 _col35 _col36 _col37 _col38 _col39 0 1 1 5283 4 0 21 33 1 1 2 3 204 310 1640 6 4 6 2 4 7 29 2 11 66 2 22 3 9 43 2 10 286 6 2 0 4 0 477 10 6 0 2 0 30
数据相关属性:
以生成模拟数据为例:
# generate_data.py import hugectr from hugectr.tools import DataGenerator, DataGeneratorParams from mpi4py import MPI import argparse parser = argparse.ArgumentParser(description=("Data Generation")) parser.add_argument("--num_files", type=int, help="number of files in training data", default = 8) parser.add_argument("--eval_num_files", type=int, help="number of files in validation data", default = 2) parser.add_argument('--num_samples_per_file', type=int, help="number of samples per file", default=1000000) parser.add_argument('--dir_name', type=str, help="data directory name(Required)") args = parser.parse_args() data_generator_params = DataGeneratorParams( format = hugectr.DataReaderType_t.Parquet, label_dim = 1, dense_dim = 13, num_slot = 26, num_files = args.num_files, eval_num_files = args.eval_num_files, i64_input_key = True, num_samples_per_file = args.num_samples_per_file, source = "./etc_data/" + args.dir_name + "/file_list.txt", eval_source = "./etc_data/" + args.dir_name + "/file_list_test.txt", slot_size_array = [12988, 7129, 8720, 5820, 15196, 4, 4914, 1020, 30, 14274, 10220, 15088, 10, 1518, 3672, 48, 4, 820, 15, 12817, 13908, 13447, 9447, 5867, 45, 33], nnz_array = [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], # for parquet, check_type doesn't make any difference check_type = hugectr.Check_t.Non, dist_type = hugectr.Distribution_t.PowerLaw, power_law_type = hugectr.PowerLaw_t.Short) data_generator = DataGenerator(data_generator_params) data_generator.generate()num_files:即数据集分为几个子集,也是使用ETC训练时每一个pass所用到的数据,子集数等于训练所需pass数
num_samples_per_file:也即每个子数据集的样本数
label_dim:每一个sample的标签维度
dense_dim:连续特征的数量
num_slot:分类特征的数量,也即slot数(特征域数量)
slot_size_array:每一个slot中的最大特征数量(也就是特征域的大小)
nnz_array: 样本在对应的slot (特征域)中最多可同时有几个特征(用于选择是one-hot还是multi-hot)
执行脚本生成模拟数据(总共产生8个训练数据子集和2个测试子集):
python generate_data.py --dir_name "file0"[HCTR][03:28:28.823][INFO][RK0][main]: Generate Parquet dataset [HCTR][03:28:28.823][INFO][RK0][main]: train data folder: ./etc_data/file0, eval data folder: ./etc_data/file0, slot_size_array: 12988, 7129, 8720, 5820, 15196, 4, 4914, 1020, 30, 14274, 10220, 15088, 10, 1518, 3672, 48, 4, 820, 15, 12817, 13908, 13447, 9447, 5867, 45, 33, nnz array: 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, #files for train: 8, #files for eval: 2, #samples per file: 1000000, Use power law distribution: 1, alpha of power law: 1.3 [HCTR][03:28:28.823][INFO][RK0][main]: ./etc_data/file0 exist [HCTR][03:28:28.823][INFO][RK0][main]: ./etc_data/file0/train/gen_0.parquet [HCTR][03:28:33.757][INFO][RK0][main]: ./etc_data/file0/train/gen_1.parquet [HCTR][03:28:36.560][INFO][RK0][main]: ./etc_data/file0/train/gen_2.parquet [HCTR][03:28:39.337][INFO][RK0][main]: ./etc_data/file0/train/gen_3.parquet [HCTR][03:28:42.083][INFO][RK0][main]: ./etc_data/file0/train/gen_4.parquet [HCTR][03:28:44.807][INFO][RK0][main]: ./etc_data/file0/train/gen_5.parquet [HCTR][03:28:47.641][INFO][RK0][main]: ./etc_data/file0/train/gen_6.parquet [HCTR][03:28:50.377][INFO][RK0][main]: ./etc_data/file0/train/gen_7.parquet [HCTR][03:28:53.131][INFO][RK0][main]: ./etc_data/file0/file_list.txt done! [HCTR][03:28:53.132][INFO][RK0][main]: ./etc_data/file0/val/gen_0.parquet [HCTR][03:28:55.941][INFO][RK0][main]: ./etc_data/file0/val/gen_1.parquet [HCTR][03:28:58.788][INFO][RK0][main]: ./etc_data/file0/file_list_test.txt done!输出keysets(以gen_0为例):
每一个子数据集(每个pass用的数据集)会生成一个keysets,所有数据的keysets构成一个更大的集合all_keysets,最终将根据all_keysets生成keysets文件xxx.keyset供GPU在t时刻预读取t+1时刻的数据到ETC中
------------------------ unique_keys: 0 0 1 1 2 2 3 3 4 4 ... 12115 12978 12116 12979 12117 12981 12118 12983 12119 12986 Name: _col14, Length: 12120, dtype: int64 ------------------------ unique_keys: 0 12988 1 12989 2 12990 3 12991 4 12992 ... 7077 20111 7078 20112 7079 20113 7080 20114 7081 20116 Name: _col15, Length: 7082, dtype: int64 ------------------------ unique_keys: 0 20117 1 20118 2 20119 3 20120 4 20121 ... 8554 28827 8555 28828 8556 28830 8557 28831 8558 28834 Name: _col16, Length: 8559, dtype: int64 ------------------------ unique_keys: 0 28837 1 28838 2 28839 3 28840 4 28841 ... 5798 34652 5799 34653 5800 34654 5801 34655 5802 34656 Name: _col17, Length: 5803, dtype: int64
使用ETC分pass训练示例(与上例不同,此例使用10个pass来训练):
Pass ID Number of Unique Keys Embedding size (GB) #0 24199179 11.54 #1 26015075 12.40 #2 27387817 13.06 #3 23672542 11.29 #4 26053910 12.42 #5 27697628 13.21 #6 24727672 11.79 #7 25643779 12.23 #8 26374086 12.58 #9 26580983 12.67
数据预处理时,HugeCTR将分类特征转换为整型序列的方法:
使用NVTabular:
# e.g. using NVTabular target_encode = ( ['brand', 'user_id', 'product_id', 'cat_2', ['ts_weekday', 'ts_day']] >> nvt.ops.TargetEncoding( nvt.ColumnGroup('target'), kfold=5, p_smooth=20, out_dtype="float32", )https://nvidia-merlin.github.io/NVTabular/v0.7.1/api/ops/targetencoding.html
Target encoding is a common feature-engineering technique for categorical columns in tabular datasets. For each categorical group, the mean of a continuous target column is calculated, and the group-specific mean of each row is used to create a new feature (column). To prevent overfitting, the following additional logic is applied:
Cross Validation: To prevent overfitting in training data, a cross-validation strategy is used - The data is split into k random “folds”, and the mean values within the i-th fold are calculated with data from all other folds. The cross-validation strategy is only employed when the dataset is used to update recorded statistics. For transformation-only workflow execution, global-mean statistics are used instead.
Smoothing: To prevent overfitting for low cardinality categories, the means are smoothed with the overall mean of the target variable.
2. Hashing
- 存储hashtable和embedding的数据结构是什么?
- 为什么使用hash可以节省空间??
- 是每一个分类特征对应一个hashtable吗?(但是示例合成数据里面的key都是全局的key,而不是分特征从0开始累计的)
relevant:
- <thrust/pairs.h> : 用于封装异构元素对(实现k-v)
为什么用hashing (参考:Deep Hash Embedding)
- 用于压缩embedding(将n维one-hot特征编码为m维one-hot特征,且m<n):如果不用hash,使用one-hot full embedding 的方式,则embedding将会非常庞大,因为许多低频特征也将占据大量embedding空间
- 当出现新特征时可动态扩容embedding
什么hash函数(non-cryptographic hash function)
- Identity hash function:当数据足够小的时候(如key小于int64时)可以直接将数据作为hash value。也即直接将分类特征的key作为value用于查embedding?
- murmurhash function
如何查(怎么分布式)
每一个GPU上存放着不同slot对应的hashtable,用于压缩embedding matrix,在进行数据并行,每个GPU获得输入数据后,先做all-to-all将需要查询的数据对应特征传输到存储其特征域(slot)embedding的GPU上,再在对应GPU上查表(lookup)得到embedding vector,再使用all-to-all返回查询结果到原来的GPU中,每个GPU再通过寄存器合并不同特征域的embedding作为最终输入前馈网络的数据
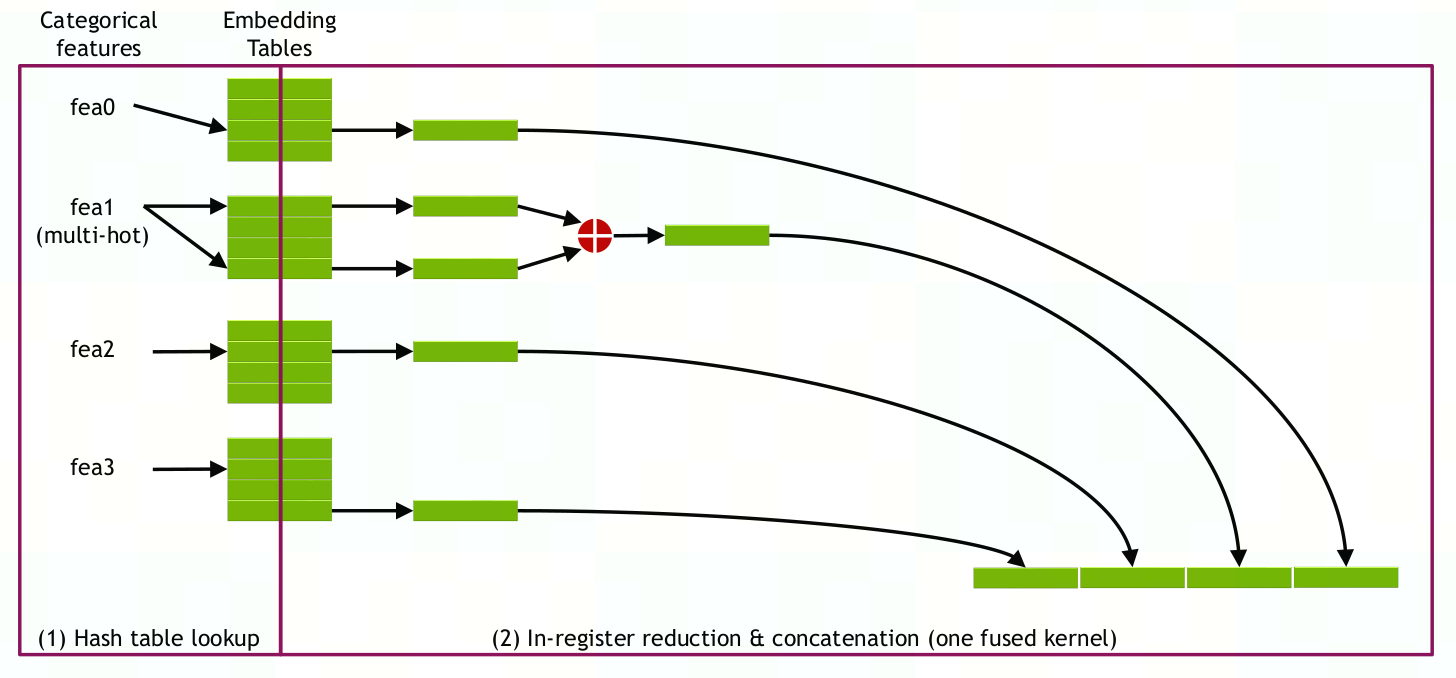
embedding前的输入数据为64位int哈希值,只有训练数据出现新的key而hashtable找不到时才在运行时插入一对k-v:
Embedding initialization is not required before training takes place since the input training data are hash values (64-bit signed integer type) instead of original indices. A pair of <key,value> (random small weight) will be inserted during runtime only when a new key appears in the training data and the hash table cannot find it.
每一个GPU中的hashtable是一样的吗?
输出hashing 的是什么,是需要传入embedding table 中的值还是直接输出embedding vector?且输出的hash是指向CPU mem还是GPU cache?
发生hash冲突如何处理?
- 业界处理方法:
- double hash:使用两个hash函数分别计算编码,再聚合(e.g. sum)
- frequency hash:只对低频特征做hashing,高频特征直接查表(identity hash?)
- 其他方法:Bloom Emb、Compositional Emb、Hash Emb
- Hugectr处理方法:
- 业界处理方法:
3. Embedding
:
embedding的插入查询先后顺序问题如何解决(读后写问题)?
- 若当前thread准备插入一个slot,发现此处key已存入但是value暂未存入,说明有其他线程正在操作当前slot,则当前thread不操作,等待其他thread插入value
embedding和hashtable内是如何搜索的?(什么搜索策略or直接计算得到?)
embedding是如何划分的,与梯度数据的关系为何?
- embedding是按照slot进行划分成一个个embedding table,然后将这些slot分布式存储在不同GPU上,每一个slot代表一个特征域,比如说用户的国籍作为一个category特征可以组成一个特征域(这里的特征域可以是多种特征融合而成的一个大的特征域)
- 而embedding层之上的前馈网络梯度数据是另外存储在GPU上的,可以看见使用SOK的代码将他们分别存储

参考实现:
美团的实现是对于ids庞大的sparse特征,将embedding分布式存储到gpus的显存中,使用gpu内hash表;
The total number of embedding parameters is tens of billions, and there are thousands of feature fields in each sample. As the range of input features is not fixed and unknown in advance, the team uses hash tables to uniquely identify each input feature before feeding into an embedding layer
hashtable只是一种存储稀疏特征embedding的方式,其他特征的存储可使用Variable存储(也即使用hash压缩embedding)
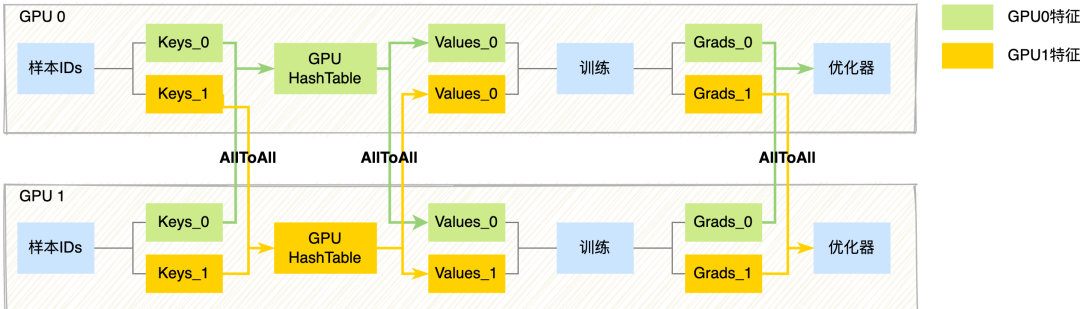
稀疏特征(ID类特征,规模较大,使用HashTable存储):由于每张卡的输入样本数据不同,因此输入的稀疏特征对应的特征向量,可能存放在其他GPU卡上。具体流程上,训练的前向我们通过卡间AllToAll通信,将每张卡的ID特征以Modulo的方式Partition到其他卡中,每张卡再去卡内的GPUHashTable查询稀疏特征向量,然后再通过卡间AllToAll通信,将第一次AllToAll从其他卡上拿到的ID特征以及对应的特征向量原路返回,通过两次卡间AllToAll通信,每张卡样本输入的ID特征都拿到对应的特征向量。训练的反向则会再次通过卡间AllToAll通信,将稀疏参数的梯度以Modulo的方式Partition到其他卡中,每张卡拿到自己的稀疏梯度后再执行稀疏优化器,完成大规模稀疏特征的优化。详细流程如下图所示:
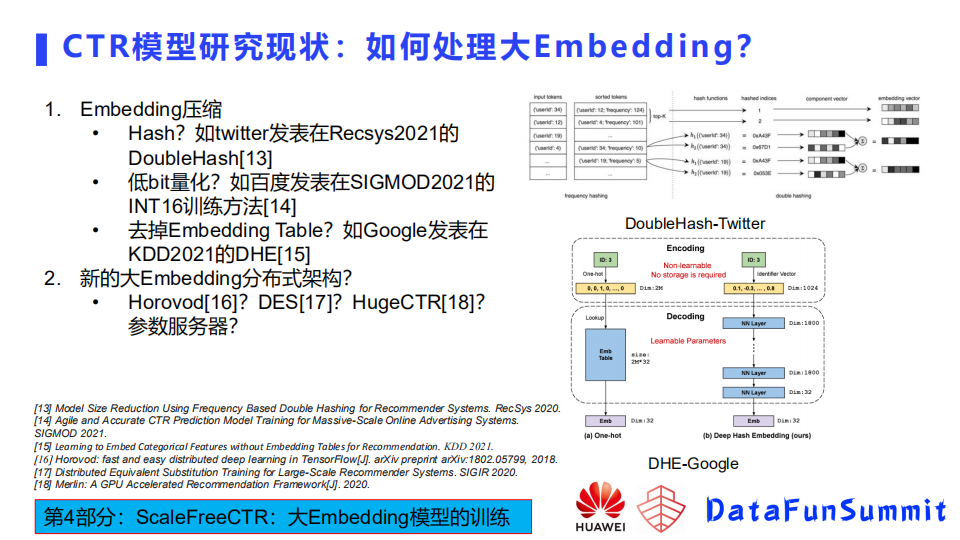
传统embedding方法:对特征进行编码,得到ID(key),用ID去embedding里面查表,得到对应的embedding(需要存放非常大的embedding),使用hashtable做压缩:将ID传入hash function,得到hashed indices,再传入embedding table得到embedding
压缩方法的话也有几个分类,这里简单提几个比较有趣的工作,第一个就是twitter在Recsys 2021发表的Double hash的方法。这种方法首先把特征分成了高频和低频,因为高频特征相对比例比较小,给每一个高频特征分配一个独立的embedding,它所占的空间也不是很大。对于低频特征,使用Double hash方法进行压缩,该hash方法是为了尽可能地减少冲突
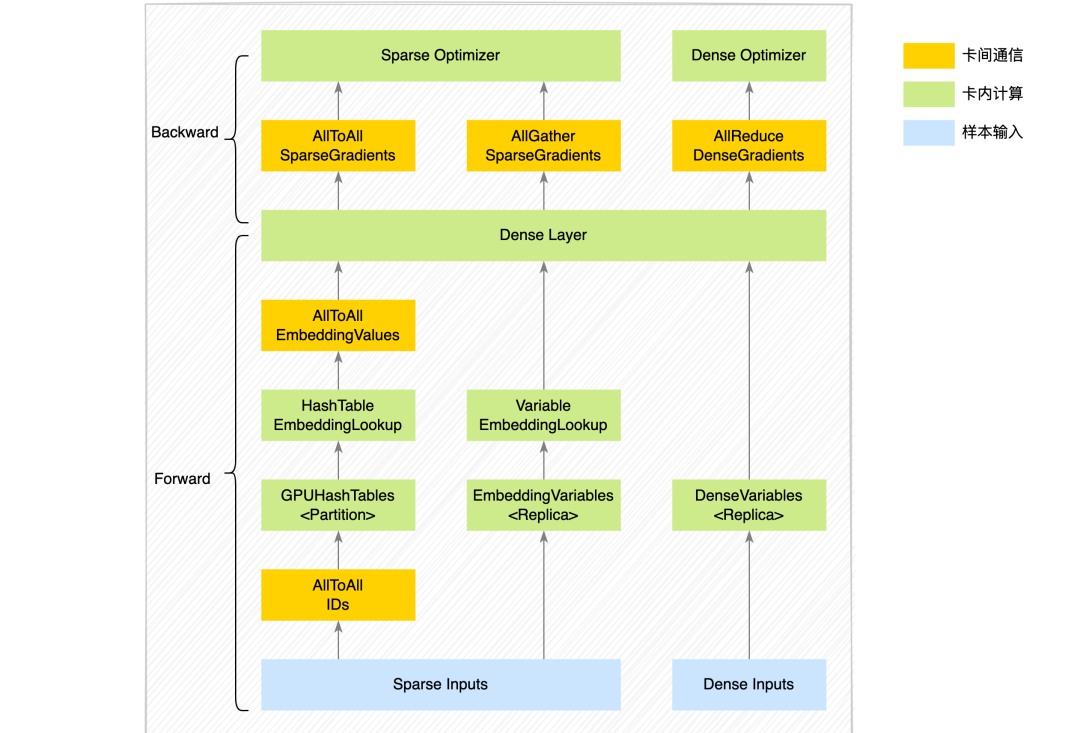
对于ids不大的sparse特征,直接使用数据副本的方式在每个gpu上存放所有特征;对于dense特征,也是使用replica方式在每个gpu上存放所有特征。
4. Other
Training Steps:
- Create the solver, reader and optimizer, then initialize the model.
- Construct the model graph by adding input, sparse embedding and dense layers in order.
- Compile the model and have an overview of the model graph.
- Dump the model graph to the JSON file.
- Fit the model, save the model weights and optimizer states implicitly.
参数服务器是如何布置的(在做数据并行时是否有某个server做master,以及master和worker的关系)
- CPU做PS,GPU做worker
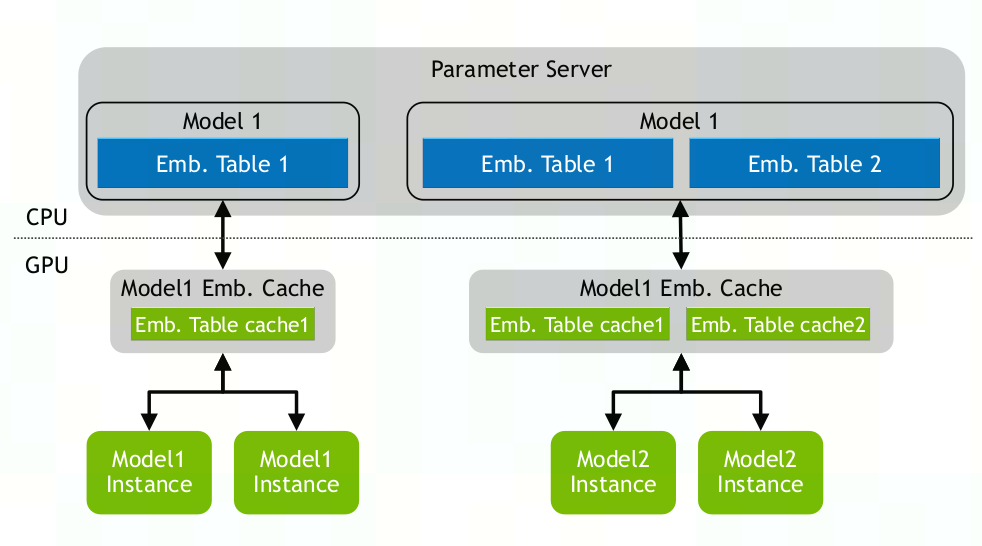
image-20221108165507297
Embedding Training Cache (ETC):
- 用于解决embedding太大无法放入GPU显存的问题
- 将数据集划分为一个个子集,训练每个子集的过程称为一个pass,每个数据集都有从category特征中提取出的keyset
- 所有key都使用与数据集分类特征相同的数据类型(uint,ll等)
- key可以以任何顺序存储
SOK项目结构(包含从父文件夹获取的HugeCTR等)
DIR Discription cmakes 用于构建项目时查找NCCL、NVTX、Tensorflow组件及判断版本号 documents 用于生成文档,包含示例代码和benchmark experiment SOK的实验性功能更新 HugeCTR HugeCTR核心功能 kit_cc kit_cc_impl notebooks SOK jupyter 示例 sparse_operation_kit sok核心功能 third_party 其他依赖项,json unit_test 单元测试,包含tf1&2单卡多卡测试 从setup.py开始编译安装sok,需要依赖于父文件夹中的HugeCTR和third_party/json
os.system("cp -r ../HugeCTR ./") os.system("mkdir third_party") os.system("cp -r ../third_party/json ./third_party/")Notes:
使用hvd时,hvd的初始化需要在最前面
使用tf1时,sok初始化要在其他变量初始化之前
sok如何使用hctr的so库,从何处编译:
hugectr/sparse_operation_kit/sparse_operation_kit/kit_lib.py: 导入libsparse_operation_kit.so
hugectr/sparse_operation_kit/sparse_operation_kit/operations/compat_ops_lib.py:导入libsparse_operation_kit_compat_ops.so
HCTR加速embedding的方法:重新实现embedding层,GPU加速的hashtable(基于RAPIDS cuDF,可实现相对CPUx35倍加速),节省内存的sparse optimizer,各种embedding分布策略,NCCL通信
sok实现了多种embedding层,部分参数有
- SparseEmbedding:
- combiner:如何合并slot内的embedding:mean或sum
- [max_vocabulary_size_per_gpu, embedding_vec_size]:embedding变量的大小
- slot_num:slot的总数,也即特征域的数量
- max_nnz:一个slot中key 的最大数量
- max_feature_num:特征的最大数,为slot_num*max_nnz
- use_hashtable:是否使用哈希表存储嵌入向量,若为False,则输入embedding层的key作为索引值查找embedding(key需在[0, max_vocabulary_size_per_gpu * gpu_num)]范围内)
- DenseEmbedding:
- [max_vocabulary_size_per_gpu, embedding_vec_size]:embedding变量的大小
- slot_num:slot的总数,也即特征域的数量
- nnz_per_slot:每个slot中key 的数量,且都相等(nnz:number of non zero非零实例,我的理解:nnz为1,则是one-hot, nnz大于1则是multi-hot)
- dynamic_input:是否输入张量的大小是动态的(非固定值)
- use_hashtable:是否使用哈希表存储嵌入向量,若为False,则输入embedding层的key作为索引值查找embedding
- SparseEmbedding:
分布式embedding的相关函数:
- sparse_operation_kit.experiment.lookup.lookup_sparse(params, sp_ids, hotness, combiners):
- 支持分布式lookup
- 支持融合查找,同时查找多个参数
- params:sok.Variable列表
- sp_ids (list*,* tuple) – tf.SparseTensor or tf.RaggedTensor的列表
- hotness (list*,* tuple) – a list or tuple of int to specify the max hotness of each lookup.??
- combiners (list*,* tuple) – 每次lookup的合并策略的列表
- sparse_operation_kit.experiment.lookup.lookup_sparse(params, sp_ids, hotness, combiners):