

Metrics
大约 4 分钟
Metrics
0. GOAL
各类评估指标整理汇总,影响因素,提升方法
1. 性能相关
基本概念
名称 内容 备注 NVLink 节点内device连接方式之一 PCIe 高速串行计算机扩展总线标准 节点内device连接方式之一 Infinit Band (IB) 节点间device连接方式(多机) ASIC 专用集成电路 FPGA 现场可编辑门阵列 SHArP 软硬结合的通信协议,实现在了NVIDIA Quantum HDR Switch的ASIC里 把聚合计算(reduce)从节点卸载到网络(交换机)中进行,相比tree和ring算法收发数据量大幅减少 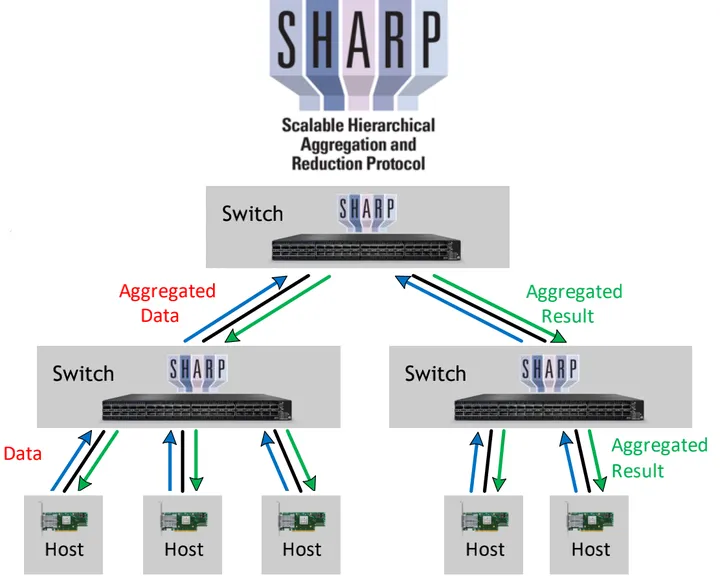 参考:https://www.zhihu.com/question/63219175/answer/206697974
参考:https://www.zhihu.com/question/63219175/answer/206697974
性能指标
名称 内容 备注 Size(Bytes) 数据大小 Description 测试描述(数据量*字节数) Duration 耗时 Throughput(Gbps, fps, ...) 吞吐,每秒处理的图片/samples/文本/...数 一般用iter e2e时间来计算:$thoughput = \frac{n_{card}*batchsize}{e2e_time}$ BusBW(Gbps) 带宽 扩展率 网络训练效率与卡数关系的衡量指标 $扩展率=\frac{throghput_{n card}}{n*throughput_{1card}}*100%=\frac{e2e_time_{1card}}{e2e_time_{ncard}}*100%$
性能测试
影响模型性能的因素:cpu性能,gpu性能,io性能,pcie带宽,卡间/机间通信带宽
- 分析工具:profiler,perf,top -c,注意各资源利用率
- 模型推理或者训练过程中,输入数据(例如一张图片)的加载,解码,预处理一般是cpu执行(dataloader和transforms)。任务下发到设备侧的过程也需要cpu执行。
- 瓶颈分析可以通过top -c看cpu利用率,profiler看设备侧执行kernel是否有空泡。
- 影响cpu发挥性能的参数有两个:CPU scaling_governor和CPU irqbalance,一个是工作频率,一个是中断请求处理。
- 磁盘io带宽影响数据读取的速度。
- pcie带宽影响h2d和d2h的速度。
- gpu做计算。显存与计算核间带宽,计算核的计算能力,运行主频影响device侧性能。(由于功耗核散热问题,当温度达到一定限度时,默认机器会自动降频,影响测试性能结果。多卡间计算耗时的不一致会导致扩展性问题)
单卡:
功耗问题导致性能下降。处理方式:找静态功耗最低的卡进行测试。
某些算子性能不达标。通过profiler对比查看和竞品的耗时差异,导出gencase,优化算子性能。
cpu下发慢,或者预处理加载数据问题。通过profiler查看cpu加载和预处理的耗时占整个推理的比例以及device侧是否有空泡。处理方式:更换更好的cpu,查看cpu是否充分利用,通过修改与数据加载相关的参数充分利用cpu(dataloader类的num_works多进程读取数据,pin_memory加速h2d)。pillow版本,使用pillow-simd进行预处理加速(主要的图像处理包:
gpu利用率低,profiler查看gpu执行算子是否有空泡,考虑增加batchsize,增加算子吞吐,提高gpu利用率。(查看带宽和ipu利用率,判断是io瓶颈或者计算瓶颈)
注意,真实数据和权值测试的性能有时不能用假数据进行模拟,因为某些情况下随机数据和真实数据分布不一致,算子设计没考虑,导致算子性能下降,或者引起功耗问题而降频。
单卡到多卡的扩展性影响因素:
- 卡间带宽,卡间互联方式及带宽。还要考虑是不是会因为功耗墙问题导致某个卡降频而block掉其他卡的性能。(通过查看工作温度和功耗可以基本判断),处理方式,测试时锁频或者开大风扇
多机通信:
- 机间通信方式