

Distributed_embeddings
大约 4 分钟
Distributed_embeddings
1. Introduce
参考链接:
- 项目地址:https://github.com/NVIDIA-Merlin/distributed-embeddings
- 相关blog:https://developer.nvidia.com/blog/fast-terabyte-scale-recommender-training-made-easy-with-nvidia-merlin-distributed-embeddings/
- 相关项目:https://github.com/NVIDIA/DeepLearningExamples/tree/master/TensorFlow2/Recommendation/DLRM#hybrid-parallel-training-with-merlin-distributed-embeddings
- 项目文档:https://nvidia-merlin.github.io/distributed-embeddings/index.html
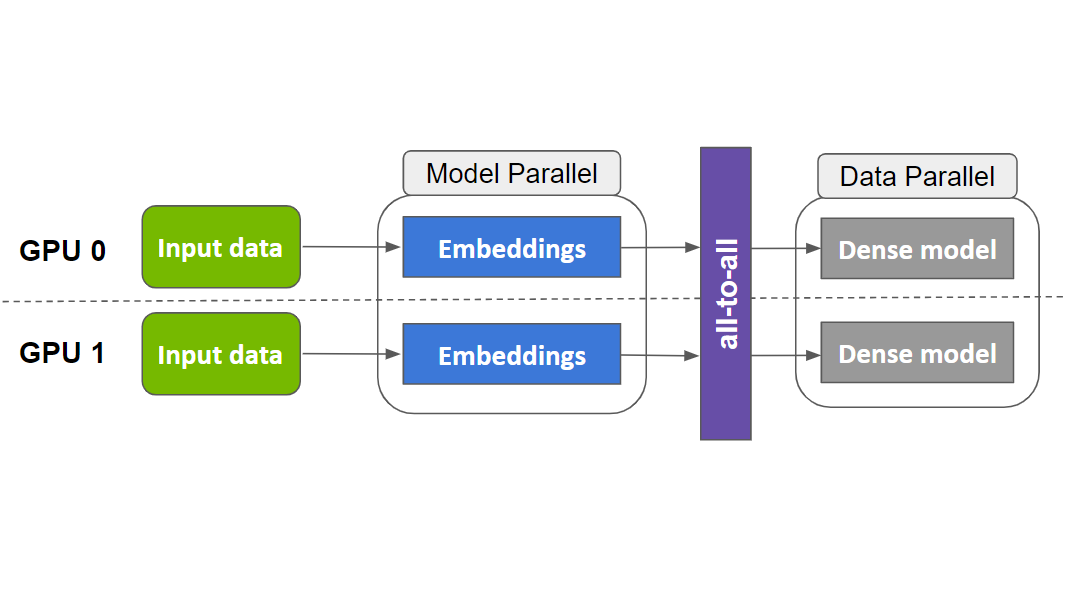
基于TF2构建大embedding,提供可伸缩模型并行封装器,能够自动将嵌入表分布到多GPU上(目前支持table-wise和column-wise)
支持混合模型并行(dist_model_parallel):
仅需修改少量代码即可使用
import dist_model_parallel as dmp class MyEmbeddingModel(tf.keras.Model): def __init__(self, table_sizes): ... self.embedding_layers = [tf.keras.layers.Embedding(input_dim, output_dim) for input_dim, output_dim in table_sizes] # 1. Add this line to wrap list of embedding layers used in the model self.embedding_layers = dmp.DistributedEmbedding(self.embedding_layers) def call(self, inputs): # embedding_outputs = [e(i) for e, i in zip(self.embedding_layers, inputs)] embedding_outputs = self.embedding_layers(inputs) @tf.function def training_step(inputs, labels, first_batch): with tf.GradientTape() as tape: probs = model(inputs) loss_value = loss(labels, probs) # 2. Change Horovod Gradient Tape to dmp tape # tape = hvd.DistributedGradientTape(tape) tape = dmp.DistributedGradientTape(tape) grads = tape.gradient(loss_value, model.trainable_variables) opt.apply_gradients(zip(grads, model.trainable_variables)) if first_batch: # 3. Change Horovod broadcast_variables to dmp's # hvd.broadcast_variables(model.variables, root_rank=0) dmp.broadcast_variables(model.variables, root_rank=0) return loss_value示例
import tensorflow as tf import distributed_embeddings.python.layers.dist_model_parallel as dmp from distributed_embeddings.python.layers.dist_model_parallel import Embedding, DistributedEmbedding layer0 = Embedding(1000, 64, name="emb_0") layer1 = Embedding(1000, 64, combiner="mean", name="emb_1") layer2 = tf.keras.layers.Embedding(1000, 64, name="emb_2") layer3 = tf.keras.layers.Embedding(1000, 64, name="emb_3") layers0 = [layer0, layer1] layers1 = [layer2, layer3] emb_layers0 = DistributedEmbedding(layers0, column_slice_threshold=32000) emb_layers1 = DistributedEmbedding(layers1, column_slice_threshold=32000)API:
distributed_embeddings.python.layers.embedding.
Embedding
- 接口基本上对齐 tf.keras.layers.Embedding,且增加了支持同时lookup多个embedding 再将它们combine(sum/mean)为一个vector输出
- 支持多种数据类型:onehot/fixed hotness (multihot, 输入tensor维度相同)/variable hotness(multihot, 输入tensor维度不同,使用tf.RaggedTensor)/sparse tensor(multihot, 使用tf.sparse.SparseTensor,按照csr格式存储稀疏tensor)
distributed_embeddings.python.layers.dist_model_parallel.
DistributedEmbedding
- 支持按列切分embedding table,适用于emb table规模庞大且无法存入单张卡内存的情况
- 可设置column_slice_threshold参数确定切分阈值(elements num)
- 可封装共享embedding table,如两个特征域,一个表示watched_video, 一个表示browsed_video,他们的特征都是videos,因此可公用同一个emb table
性能表现:
- DLRM model with 113 billion parameters (421 GiB model size) trained on the Criteo Terabyte Click Logs dataset(官方数据,未实测)
Hardware Description Training Throughput (samples/second) Speedup over CPU 2 x AMD EPYC 7742 Both MLP layers and embeddings on CPU 17.7k 1x 1 x A100-80GB; 2 x AMD EPYC 7742 Large embeddings on CPU, everything else on GPU 768k 43x DGX A100 (8xA100-80GB) Hybrid parallel with NVIDIA Merlin Distributed-Embeddings, whole model on GPU 12.1M 683x Synthetic models benchmark (见第三节test部分benchmarks测试)
- 模型规模定义
Model Total number of embedding tables Total embedding size (GiB) Tiny 55 4.2 Small 107 26.3 Medium 311 206.2 Large 612 773.8 Jumbo 1,022 3,109.5 - 官方性能(DGX-A100-80GB, batchsize=65536, optimizer=adagrad )
Model Training step time (ms) Training step time (ms) Training step time (ms) Training step time (ms) Training step time (ms) Model 1 GPU 8 GPU 16 GPU 32 GPU 128 GPU Tiny 17.6 3.6 3.2 Small 57.8 14.0 11.6 7.4 Medium 64.4 44.9 31.1 17.2 Large 65.0 33.4 Jumbo 102.3 - 实测性能(Tesla T4, batchsize=65536, optimizer=adagrad)
Model Training step time (ms) Training step time (ms) Model 1 GPU 4 GPU Tiny 42.703 82.856 - 对比TF原生数据并行
Solution Training step time (ms) Training step time (ms) Training step time (ms) Training step time (ms) Solution 1 GPU 2 GPU 4 GPU 8 GPU NVIDIA Merlin Distributed Embeddings Model Parallel 17.7 11.6 6.4 4.2 Native TensorFlow Data Parallel 19.9 20.2 21.2 22.3
2. build
docker
docker run -it \ --name="distributed_embedding" \ --net host \ --gpus all \ -v /data:/data \ -v /tmp:/tmp \ -v /home:/home \ --shm-size '64gb' \ --privileged nvcr.io/nvidia/tensorflow:22.12-tf2-py3 /bin/bash docker run -it \ --name="distributed_embedding" \ --net host \ --gpus all \ -v /data:/data \ -v /tmp:/tmp \ -v /home:/home \ --shm-size '64gb' \ --privileged nvcr.io/nvidia/tensorflow:23.03-tf2-py3 /bin/bashbuild
cd /workspace git clone https://github.com/NVIDIA-Merlin/distributed-embeddings.git cd /workspace/distributed-embeddings git submodule update --init --recursive make pip_pkg && pip install artifacts/*.whl export HOROVOD_GPU_OPERATIONS=NCCL && pip install horovod==0.27 python -c "import distributed_embeddings"
2. test&benchmark
API测试
#test cd /workspace/distributed-embeddings/tests python dist_model_parallel_test.py python embedding_test.pybenchmarks测试
#benchmarks cd /workspace/distributed-embeddings/examples/benchmarks/synthetic_models # single gpu python main.py --model tiny --optimizer adagrad --batch_size 65536 # multiple gpus horovodrun -np 4 python main.py --model tiny --optimizer adagrad --batch_size 65536 --column_slice_threshold $((1280*1048576))$ python main.py --model tiny --optimizer adagrad --batch_size 65536 2023-05-30 09:39:20.547772: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1637] Created device /job:localhost/replica:0/task:0/device:GPU:0 with 13745 MB memory: -> device: 0, name: Tesla T4, pci bus id: 0000:3b:00.0, compute capability: 7.5 I0530 09:39:20.613760 139850810697536 synthetic_models.py:143] 55 embedding tables created. I0530 09:39:20.630478 139850810697536 synthetic_models.py:83] Generated 58 categorical inputs for 55 embedding tables Initial loss: 1.074 Benchmark step [0/100] Benchmark step [50/100] loss: 0.738 Iteration time: 42.703 ms =============================================================================== $ horovodrun -np 4 python main.py --model tiny --optimizer adagrad --batch_size 65536 --column_slice_threshold $((1280*1048576)) [1,2]<stderr>:2023-05-30 09:43:56.845312: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1637] Created device /job:localhost/replica:0/task:0/device:GPU:0 with 13745 MB memory: -> device: 2, name: Tesla T4, pci bus id: 0000:af:00.0, compute capability: 7.5 [1,0]<stderr>:2023-05-30 09:43:56.854465: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1637] Created device /job:localhost/replica:0/task:0/device:GPU:0 with 13745 MB memory: -> device: 0, name: Tesla T4, pci bus id: 0000:3b:00.0, compute capability: 7.5 [1,3]<stderr>:2023-05-30 09:43:56.857031: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1637] Created device /job:localhost/replica:0/task:0/device:GPU:0 with 13745 MB memory: -> device: 3, name: Tesla T4, pci bus id: 0000:d8:00.0, compute capability: 7.5 [1,1]<stderr>:2023-05-30 09:43:56.859317: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1637] Created device /job:localhost/replica:0/task:0/device:GPU:0 with 13745 MB memory: -> device: 1, name: Tesla T4, pci bus id: 0000:5e:00.0, compute capability: 7.5 [1,2]<stderr>:I0530 09:43:56.907896 140019202987840 synthetic_models.py:143] 55 embedding tables created. [1,2]<stderr>:I0530 09:43:56.922748 140019202987840 synthetic_models.py:83] Generated 58 categorical inputs for 55 embedding tables [1,0]<stderr>:I0530 09:43:56.935591 140299773019968 synthetic_models.py:143] 55 embedding tables created. [1,3]<stderr>:I0530 09:43:56.944558 140711478306624 synthetic_models.py:143] 55 embedding tables created. [1,0]<stderr>:I0530 09:43:56.950328 140299773019968 synthetic_models.py:83] Generated 58 categorical inputs for 55 embedding tables [1,3]<stderr>:I0530 09:43:56.960225 140711478306624 synthetic_models.py:83] Generated 58 categorical inputs for 55 embedding tables [1,1]<stderr>:I0530 09:43:56.962677 140080325678912 synthetic_models.py:143] 55 embedding tables created. [1,1]<stderr>:I0530 09:43:56.983801 140080325678912 synthetic_models.py:83] Generated 58 categorical inputs for 55 embedding tables [1,1]<stdout>:Initial loss: 1.256 [1,0]<stdout>:Initial loss: 1.256 [1,2]<stdout>:Initial loss: 1.256 [1,3]<stdout>:Initial loss: 1.256 [1,0]<stdout>:Benchmark step [0/100] [1,0]<stdout>:Benchmark step [50/100] [1,0]<stdout>:loss: 0.759 [1,0]<stdout>:Iteration time: 82.856 msdlrm测试
# dlrm cd /workspace/distributed-embeddings/examples/dlrm horovodrun -np 4 python main.py