

HugeCTR 学习笔记
HugeCTR 学习笔记
1 背景
1.1 推荐系统与深度学习
随着互联网的发展,受益于数据爆炸式地增长,用户获取信息的途径与方式越来越轻松多样,但也因为其中夹杂着大量庞杂冗余甚至无用的信息,如何提供用户真正感兴趣的内容也成为了各大企业尤其是商业领域重点关的问题。推荐系统就是从海量的数据中,根据用户偏好为其选择出可能感兴趣的内容并推送给用户
CTR(Click-trough rate)也即点击率,是用于评估广告、搜索内容、博文等质量、搜索相关程度以及用户喜爱程度的重要指标,也能反馈给信息提供者所推荐给用户的内容是否合适、质量是否上乘、该内容是否选对了潜在受众。CTR的定义为内容被用户点击的次数除以内容展示给用户的次数,e.g. 一条广告被用户刷到了100次,但用户只点进去了1次,那么点击率就是1%
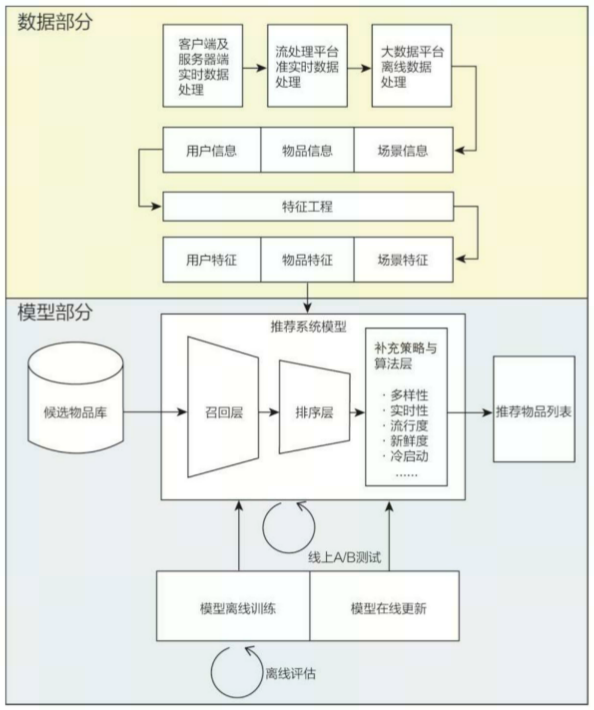
从技术架构上,可将推荐系统分为数据与模型部分:
- 数据部分主要负责“用户”“物品”“场景”的信息收集与处理;
- 模型部分是推荐系统的主体,模型的结构一般由“召回层”“排序层”“补充策略与算法层”组成:
- 召回层:一般利用高效的召回规则、算法或简单的模型,快速从海量的候选集中召回用户可能感兴趣的物品
- 排序层:利用排序模型对初筛的候选集进行精排序
- 补充策略与算法层:也被称为“再排序层”,可以在将推荐列表返回用户之前,为兼顾结果的“多样性”“流行度”“新鲜度”等指标,结合一些补充的策略和算法对推荐列表进行一定的调整,最终形成用户可见的推荐列表
img 与传统推荐系统实现方式相比,深度学习推荐模型具有更强的表达能力,模型结构更加灵活能够适应不同的使用场景,但现代推荐系统及使用场景有以下特点与难点:
现代推荐模型合并了TB级别的嵌入表,传统推理服务架构无法将整个模型部署到单个服务器上(高时延、高存储占用)
许多推荐场景需要支持在线推理与模型更新,要求低时延
查找embedding的过程是独立的,因此容易实现并行化(GPU:higher bandwidth & throughput),但也需要占用大量内存资源和少量的计算资源(不平衡的资源需求降低了GPU在推理系统中的吸引力)→ 大多现存解决方案将嵌入查找操作与在GPU中的稠密计算相解耦,放入CPU中进行(放弃GPU带宽优势,CPU与GPU间的通信带宽成为首要瓶颈)
现实世界推荐数据集的经验证据表明,在 CTR 和其他推荐任务的推理过程中嵌入key访问通常表现出很强的局部性,并且大致遵循幂律分布,具有长尾效应 (大量特征的embedding总和占据了整个模型的大部分,但是他们出现的频率非常低,因此将这种特征长期存储在CPU和GPU中是低效的)
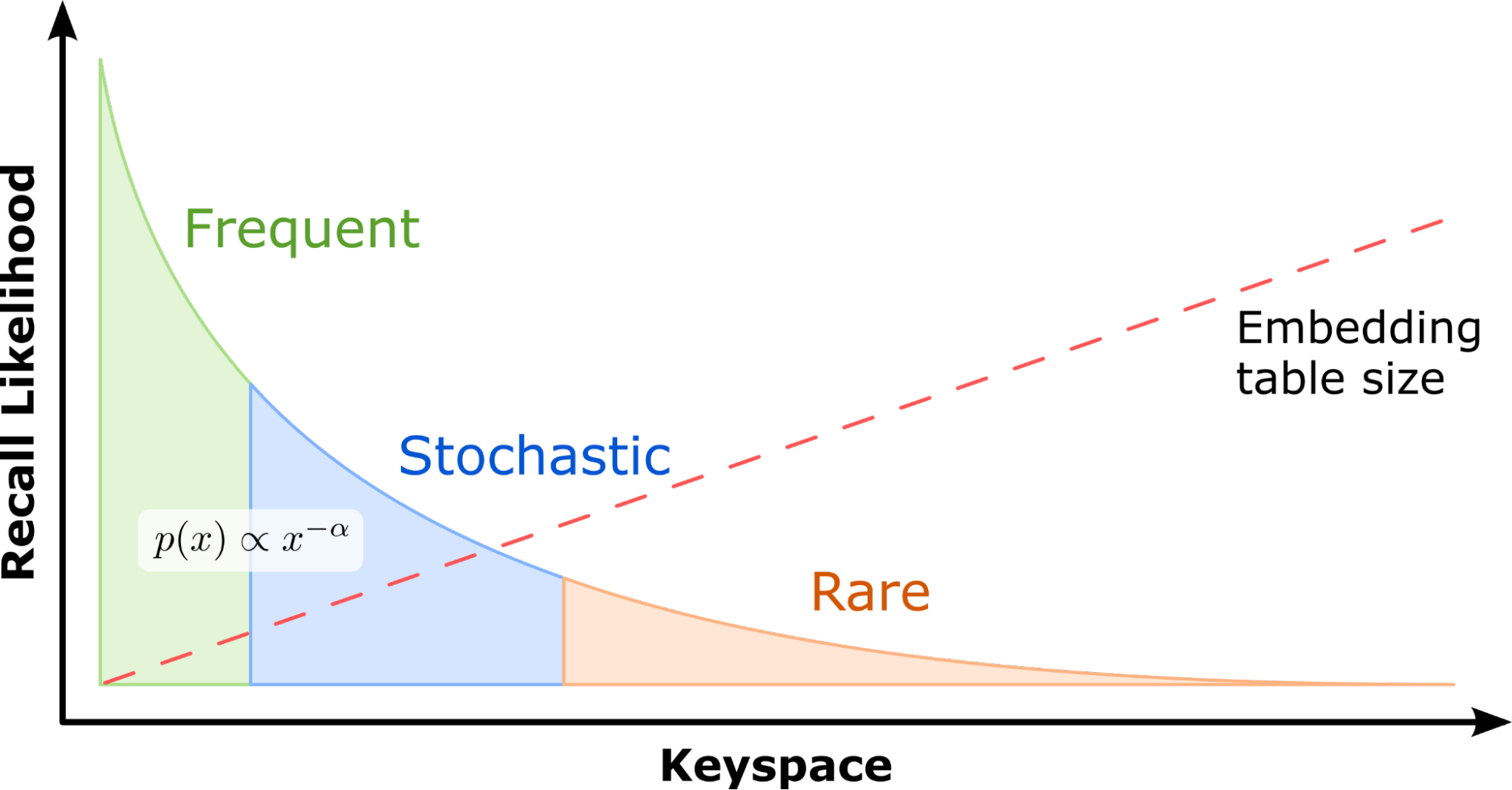
Visualization of power law distribution representing the likelihood of embedding key accesses. A few embeddings are accessed far more often than the others.
1.2 Merlin
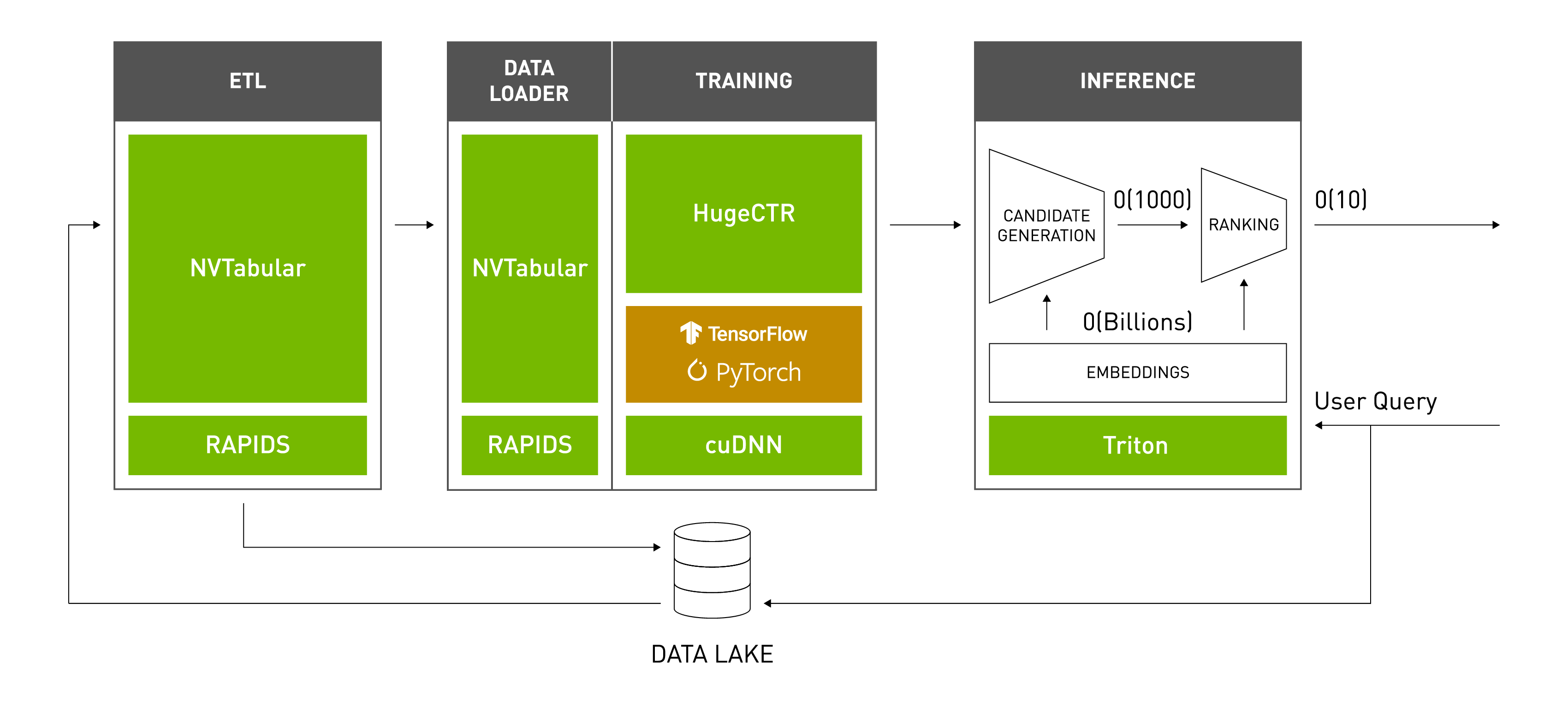
- Merlin 是NVIDIA为推荐系统模型推理训练专门构建的一套端到端解决方案,包括库、方法和工具,通过解决常见的预处理、特征工程、训练、推理和部署到生产来简化推荐系统的构建。Merlin 组件和功能经过优化,可支持数百 TB 数据的检索、过滤、评分和排序,所有这些都可通过易于使用的 API 访问。
- 它包括NVTabular、HugeCTR、Merlin Models、Merlin Systems、Merlin Core等组件:
NVTabular:NVTabular 是一个表格数据的特征工程和预处理库。该库可以快速轻松地操作用于训练基于深度学习的推荐系统的 TB 级数据集。该库提供了一个高级 API,可以定义复杂的数据转换工作流程
HugeCTR:HugeCTR 是一个 GPU 加速的训练框架,可以通过跨多个 GPU 和节点分布训练来扩展大型深度学习推荐模型。 HugeCTR 包含具有 GPU 加速的优化数据加载器,并提供了将大型嵌入表扩展到可用内存之外的策略
Merlin Models:Merlin 模型库为推荐系统提供标准模型,旨在实现从经典机器学习模型到高度先进的深度学习模型的高质量实现
Merlin Systems:Merlin Systems 提供的工具可将推荐模型与生产推荐系统的其他元素(如特征存储、最近邻搜索和探索策略)组合成端到端的推荐管道,这些管道可以通过 Triton 推理服务器提供服务
Merlin Core:Merlin Core 提供在整个 Merlin 生态系统中使用的功能
img 
img
2 介绍
- HugeCTR是由NVIDIA发布开源的使用 CUDA C++ 编写专用于大型推荐系统模型使用GPU进行训练与推理的深度学习框架,利用了 GPU 加速库,例如cuBLAS、cuDNN和NCCL,针对 NVIDIA GPU 的性能进行了高度优化,同时允许用户以 JSON 格式自定义模型
2.1 特性&发布记录
速度:单节点A100设备上可在1.7min内训练mlperf v2.0 DLRM
规模:多节点模型并行、hierarchical解决方案
使用:类似Keras的 Python API
核心特征:使用GPU中的哈希表和动态插入实现分布式embedding、异步与多线程数据流水、分层参数服务器(HPS)做推理、Tensorflow embedding插件(SOK)
2019 v1.x 发布原型系统来展示网络训练加速效果
2020 v2.x 作为组件加入Merlin中,并获得了同年的mlperf v0.7 DLRM 8卡测试第一
2021 v3.x 支持使用hierarchical 参数服务器做推理,支持作为tensorflow插件使用其embedding方法
2022 v4.0 发布新的解耦embedding组件来支持其生态
2.2 性能
HugeCTR vs Tensorflow:
HugeCTR 在Criteo数据集(广告点击率数据集)上20-core Intel Xeon CPU E5-2698 v4 和 V100 16GB GPU 训练2X1024 FC layers WDL(Wide Deep Learning)的性能:在batchsize为512时相对Tensorflow-CPU实现了114倍加速,相对Tensorflow-GPU实现7.4倍加速
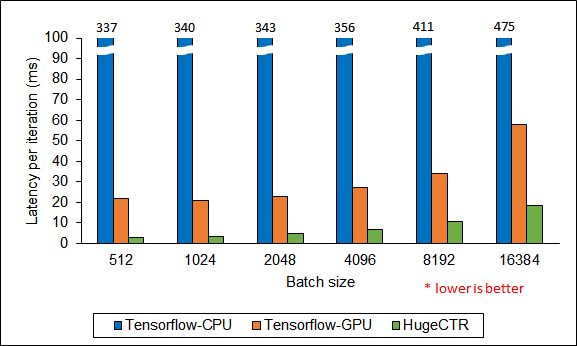
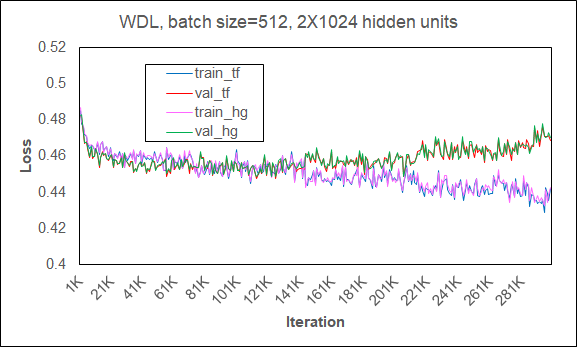
在强伸缩(也即问题规模不变,只有设备数量伸缩)下训练WDL的结果:
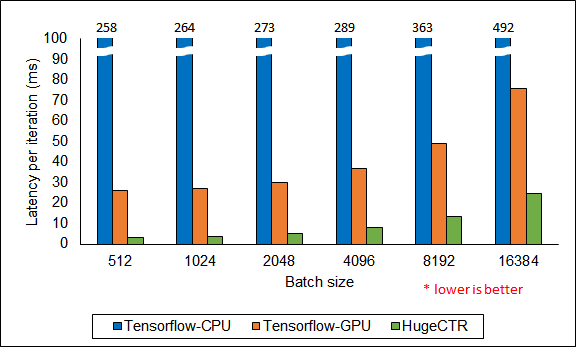
img HugeCTR 在Criteo数据集上20-core Intel Xeon CPU E5-2698 v4 和 V100 16GB GPU 训练2X1024 FC layers DCN (Deep Cross Network)的性能:在batchsize为512时相对Tensorflow-CPU实现了83倍加速,相对Tensorflow-GPU实现8.3倍加速
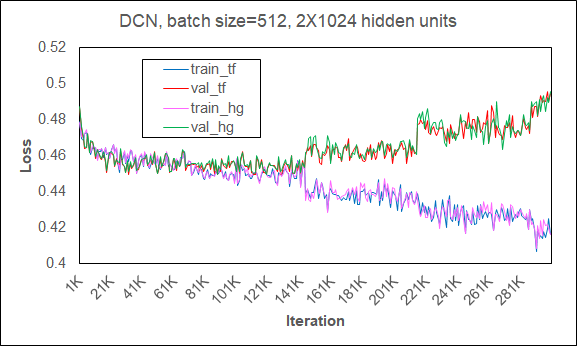
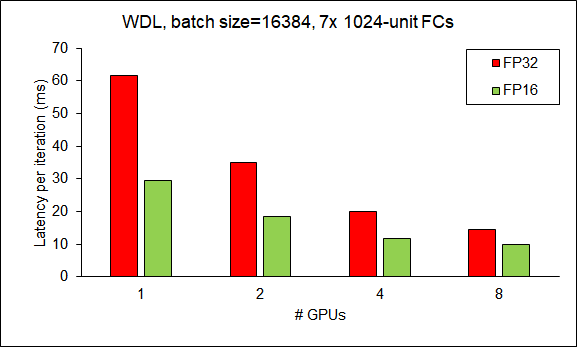
在强伸缩(也即问题规模不变,只有设备数量伸缩)下训练DCN的结果:
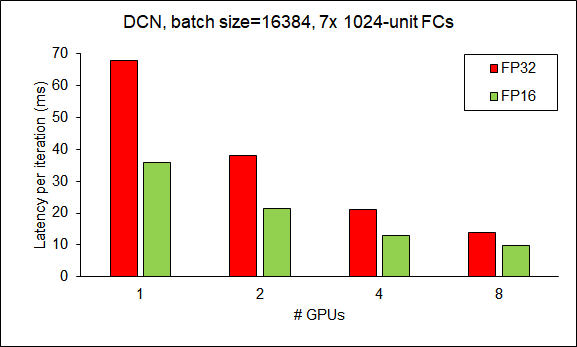
Scalability of HugeCTR from 1 GPU to 8 GPUs (DCN).
HugeCTR vs Pytorch:
Criteo数据集1下对使用Pytorch 训练DLR做对比:
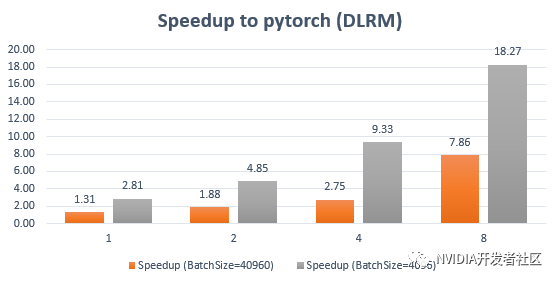
img HugeCTR在 NVIDIA DGX A100 80GB 上使用TensorFlow嵌入插件,单卡达到7.9倍加速
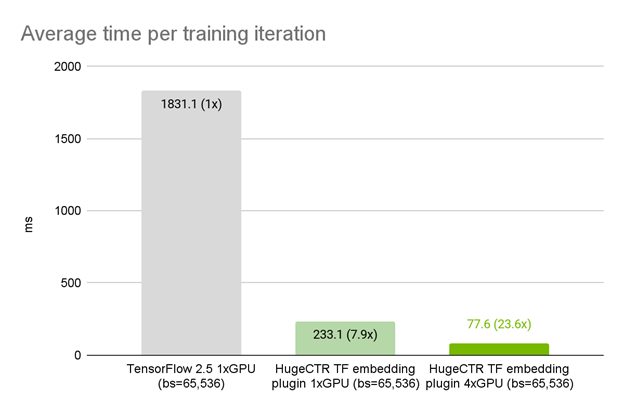
HugeCTR TensorFlow plugin provides a 7.9x speedup over native TensorFlow 2.5 embedding lookup layer. 美团数据上 NVIDIA DGX A100 80GB 上的 HugeCTR TensorFlow 嵌入插件性能(弱伸缩,也即问题规模和设备规模同时伸缩),达到11.6倍加速
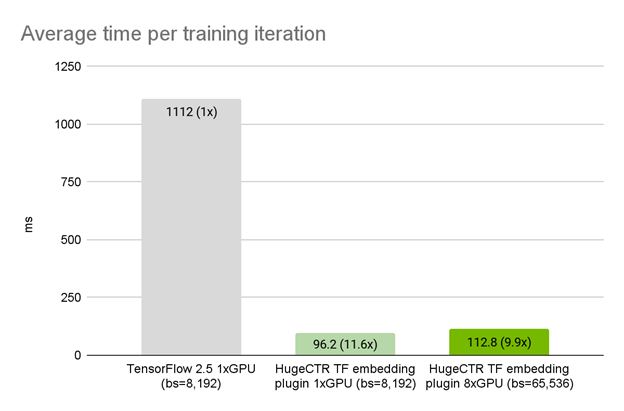
On a real use case, HugeCTR TensorFlow plugin provides a 11.6x speedup over native TensorFlow 2.5 embedding lookup layer.
HugeCTR vs HugeCTR SOK:
- 使用 MLPerf 的推荐领域标准模型 DLRM 来对 SOK 的性能进行测试,相比于 NVIDIA 的 DeepLearning Examples,使用 SOK 可以获得更快的训练速度以及更高的吞吐量
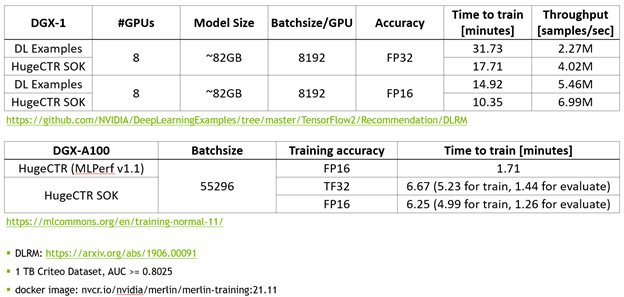
img
MLPerf v2.0:
ID System Processor # Accelerator # Software DLRM 2.0-2120 tpu-v4-256 AMD Rome 64 TPU-v4 128 Tensorflow 0.561 2.0-2098 dgxa100_n14_ngc22.04_merlin_hugectr AMD EPYC 7742 28 NVIDIA A100-SXM-80GB 112 merlin_hugectr NVIDIA Release 22.04 0.588 2.0-2093 dgxa100_n8_ngc22.04_merlin_hugectr AMD EPYC 7742 16 NVIDIA A100-SXM-80GB 64 merlin_hugectr NVIDIA Release 22.04 0.653 2.0-2068 NF5688M6 Intel(R) Xeon(R) Platinum 8358 2 NVIDIA A100-SXM-80GB CTS 8 hugectr 1.597 2.0-2064 NF5488A5 AMD EPYC 7713 64-Core Processor 2 NVIDIA A100-SXM-80GB CTS 8 hugectr 1.604 2.0-2060 R5500G5-Intelx8A100-SXM-80GB Intel(R) Xeon(R) Platinum 8378A CPU @ 3.00GHz 2 NVIDIA A100-SXM-80GB 8 NGC MXNet 22.04 , NGC PyTorch 22.04 , NGC TensorFlow 22.04-tf1 1.611 2.0-2038 PRIMERGY-GX2570M6-hugectr Intel(R) Xeon (R) Platinum 8352V 2 NVIDIA A100-SXM-80GB 8 Hugectr NVIDIA Release 22.04 1.628 2.0-2041 G492-ID0 Intel(R) Xeon(R) Platinum 8380 2 NVIDIA A100-SXM-80GB 8 hugectr 1.637 2.0-2089 dgxa100_ngc22.04_merlin_hugectr AMD EPYC 7742 2 NVIDIA A100-SXM-80GB 8 merlin_hugectr NVIDIA Release 22.04 1.697 2.0-2116 SYS-420GP-TNAR Intel(R) Xeon(R) Platinum 8380 CPU @ 2.30GHz 2 NVIDIA A100-SXM-80GB 8 Hugectr NVIDIA Release 22.04 1.729 2.0-2000 ND96amsr_A100_v4_n1 AMD EPYC 7V12 64-Core Processor 2 NVIDIA A100-SXM-80GB 8 merlin_hugectr NVIDIA Release 22.04 1.849 2.0-2015 ESCN4A-E11 AMD EPYC 7773X 1 NVIDIA A100-SXM-80GB 4 NVIDIA Release 22.04 Tensorflow, MxNet, pytorch, hugectr 3.143 2.0-2058 R5300G5x4A100-SXM-80GB Intel(R) Xeon(R) Platinum 8362 CPU @ 2.80GHz 2 NVIDIA A100-SXM-80GB 4 NGC MXNet 22.04 , NGC PyTorch 22.04 , NGC TensorFlow 22.04-tf1 3.144 2.0-2076 Lenovo ThinkSystem SR670 V2 Server with 4x 80GB SXM4 A100 Intel(R) Xeon(R) Platinum 8360Y CPU @ 2.40GHz 2 NVIDIA A100-SXM-80GB CTS 4 NGC MXNet 20211013 3.303 2.0-2034 XE8545x4A100-SXM-80GB AMD EPYC 7763 64-Core Processor 2 NVIDIA A100-SXM-80GB CTS 4 NGC MXNet 22.05 , NGC PyTorch 22.05 , NGC TensorFlow 22.05-tf1 4.309 2.0-2057 R5300G5x8A100-PCIE-80GB Intel(R) Xeon(R) Platinum 8362 CPU @ 2.80GHz 2 NVIDIA A100-PCIe-80GB 8 NGC MXNet 22.04 , NGC PyTorch 22.04 , NGC TensorFlow 22.04-tf1 5.281 2.0-2086 X640G40_8xA30_hugectr Intel(R) Xeon(R) Platinum 8380 CPU 2 NVIDIA A30 8 hugectr 5.468
2.3 架构&模块设计
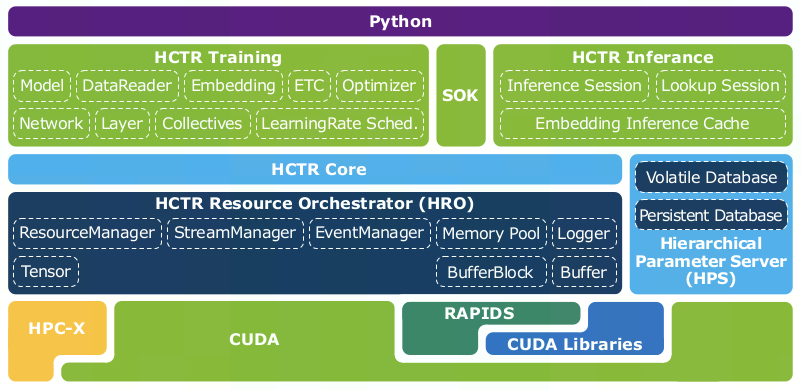
2.3.1 Training
CTR估计的DL模型(a):
分批读取包含高维、极其稀疏特征的数据
使用Embedding层压缩输入特征为低维、稠密的嵌入向量
使用前馈神经网络估计点击率
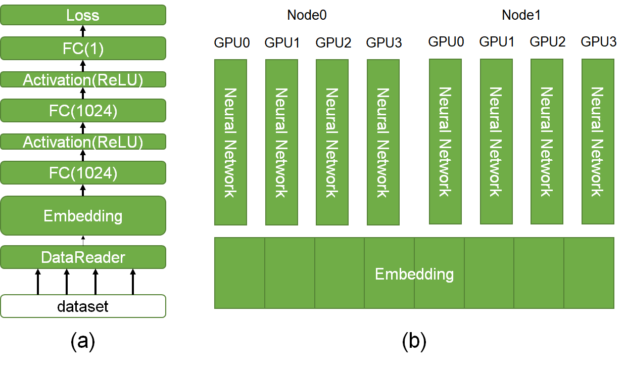
The left figure (a) shows a typical CTR model including data reader, embedding, and a fully connected layer. The right figure (b) depicts the HugeCTR architecture extensible to multiple GPUs and nodes. HugeCTR结构(基于CTR DL模型)(b):
HugeCTR 利用数据和模型并行来扩展训练,并将一个嵌入表分布于多个 GPU 之上:
数据并行:作用于前馈神经网络部分,适用于当前流行的WDL、DCN、DeepFM、DLRM等
模型并行:作用于embedding层,利用ETC模块及存储在GPU中的哈希表可支持单设备训练TB级模型
Embedding Training Cache (ETC)
特点:
- 可重新或增量训练模型
- 解决单个GPU无法存放整个模型的问题(训练前预取嵌入表所需部分,i.e. hot-embedding)
- 实现模型并行
概念:
pass:HugeCTR数据集被划分为多个文件,训练一组文件的过程称为一个pass,每个pass能够训练的embedding子集最大大小为所有GPU内存总和
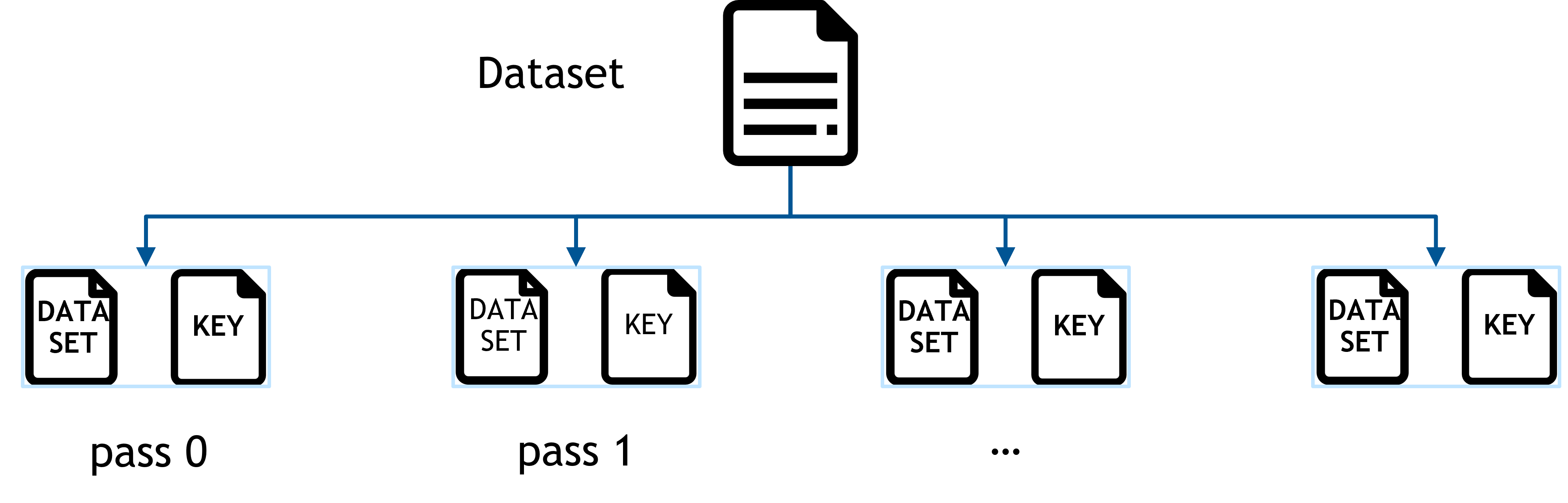
_images/etc_preprocessing.png keyset:从每个pass中提取的key集合,用于ETC预取所需embedding特征(分配对应大小内存)
slot: 特征字段或表,同一关联特征的集合,一个slot中的特征可以是one-hot或multi-hot,不同slot中的特征不能有交集
基于GPU的参数服务器:
用于加载和管理嵌入表,对于超过 GPU 显存的嵌入表,参数服务器将嵌入表存储在 CPU 内存上。对于每个子数据集,将加载所需的嵌入向量并执行多个批量更新。之后,在参数服务器中同步模型参数。
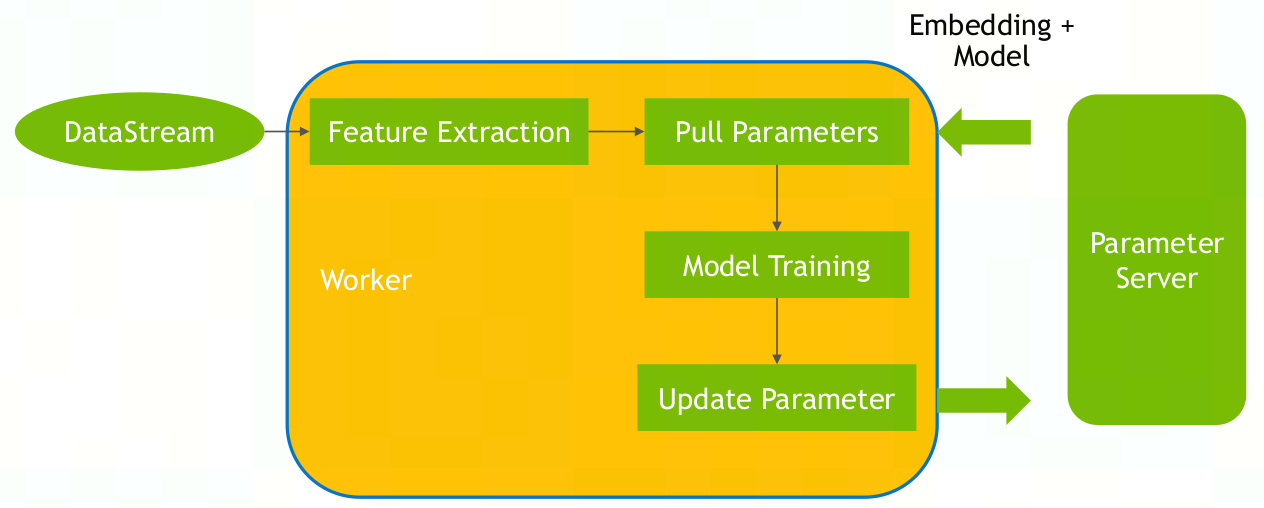
img
Embedding:
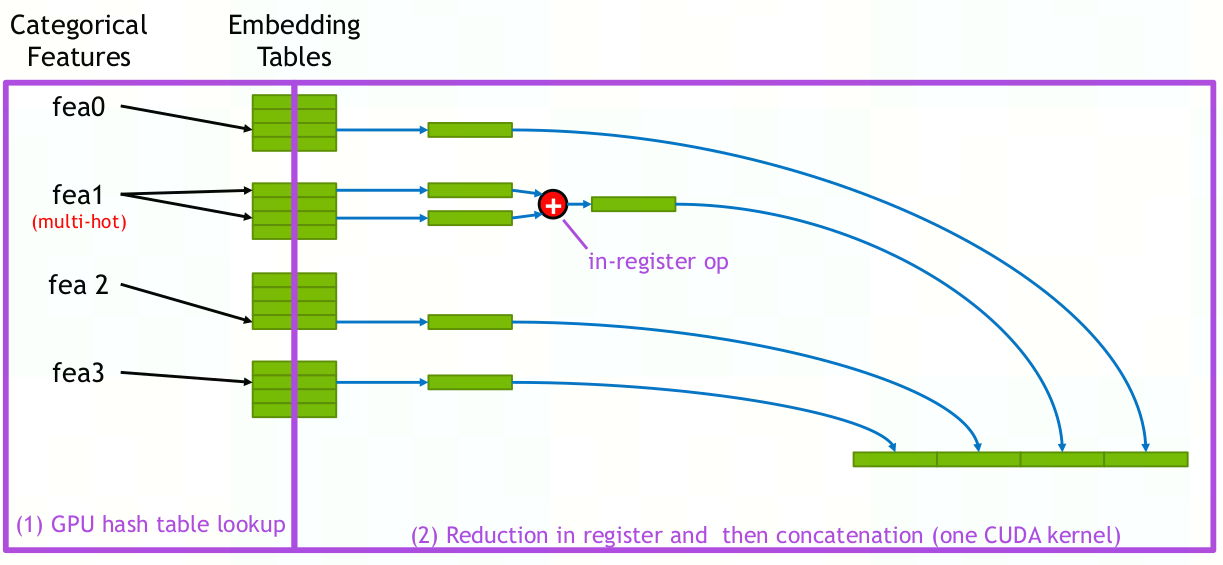
image-20221028092530696 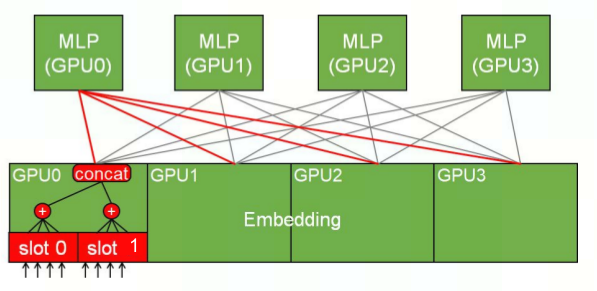
- 嵌入表可以分割成多个slot,在嵌入查找过程中,属于同一个slot的输入稀疏特征在独立转换为相应的密集嵌入向量后,被规约为单个嵌入向量。之后,不同slot的嵌入向量将拼接在一起(all-to-all)
- HugeCTR支持三种embedding方式:
- Localized slot embedding hash:所有属于同一slot的embedding存储在同一个GPU中,适用于单个slot恰好能存入GPU内存的情况,slot规约时无需做GPU间通信
- Distributed slot embedding hash:所有特征都分布式存储在不同GPU中,适用于单个slot embedding大于GPU内存的情况,但也因此需要更多的GPU间通信
- Hybrid sparse embedding:实现工业级性能推荐系统训练的关键技术,结合了数据与模型并行。
- 数据并行:前向反向传播时,本地缓存用于加速高频embedding避免了GPU间通信
- 模型并行:对于低频embedding,利用所有可用的GPU内存实现负载均衡存储embedding
训练过程:按顺序执行pass,每个pass先从PS载入embedding子集,进行训练,然后将训练好的嵌入表传回PS
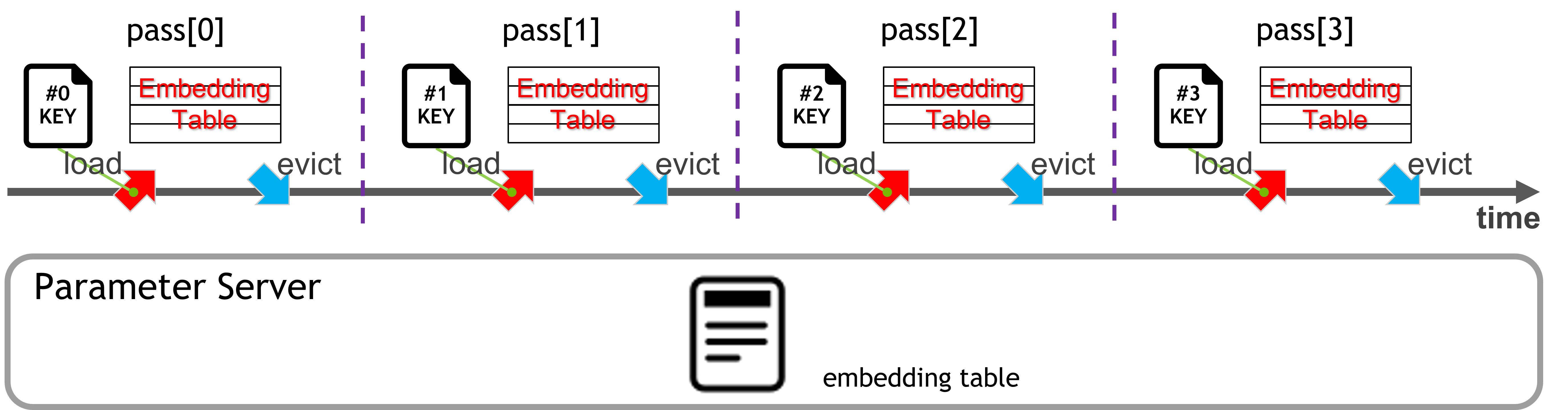
_images/etc_pipeline.png Parameter Server:
- Staged-PS:从SSD载入整个嵌入表到host内存中(支持分布式),整个ETC生命周期无需再次访问(高带宽低时延),训练完成后再存回SSD
- Cached-PS:host内存只缓存几个pass的嵌入表(克服内存对模型规模的限制)
异步和多线程的数据读取器:
- 为了防止数据加载成为训练中的主要瓶颈,Hugectr实现了多线程数据读取器隐藏数据获取延时,worker用于并行读取一批训练数据,collector用于分发数据到多卡,worker、collector、model training都在不同的线程中运行
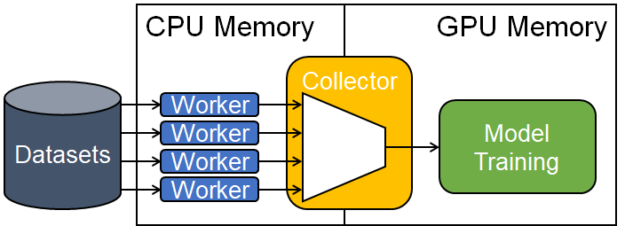
This figure shows how four data readers read data from disk to host memory, and a collector reads one of them to feed the model training pipe. - 除了多线程读取数据,还使用流水线来将不同batch的数据读取、分发与训练堆叠起来,进一步缩短数据加载耗时
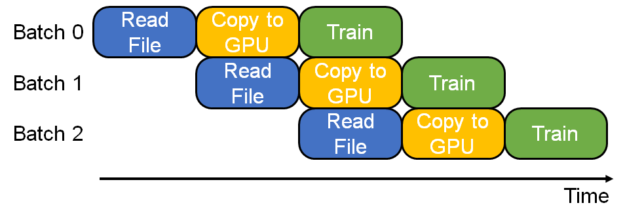
img
2.3.2 Inference
Hierarchical Parameter Server (HPS):
- 用于解决推理时embedding受GPU内存大小的限制问题
- 引入GPU嵌入缓存数据结构将热嵌入存储在GPU内存中
- 缓存从参数服务器获取热嵌入,参数服务器存放整个嵌入表
存储结构:使用三级分层缓存,利用GPU内存、分布式CPU内存以及本地SSD存储,按照数据的使用频率,存储等级由低到高为SSD→ CPU内存→ GPU内存
Embedding inference cache (level 1):使用GPU内存,动态缓存,优化的查询和操作运算符,以及动态插入和异步刷新机制,从而在在线推理期间保持高缓存命中率(利用数据局部性将常用特征(即热嵌入)保留在 GPU 内存中来减少额外/重复的参数移动)
Volatile database (VDB; level 2):使用CPU内存,当未命中GPU中参数时,在其中查询。相对于GPU内存扩展成本更低。可使用分布式Redis实例作为存储后端
Persistent database (PDB; level 3):使用SSD,保存所有模型参数,能够高效地存储长尾分布数据,提升预测精度。可使用RockDB作为存储后端
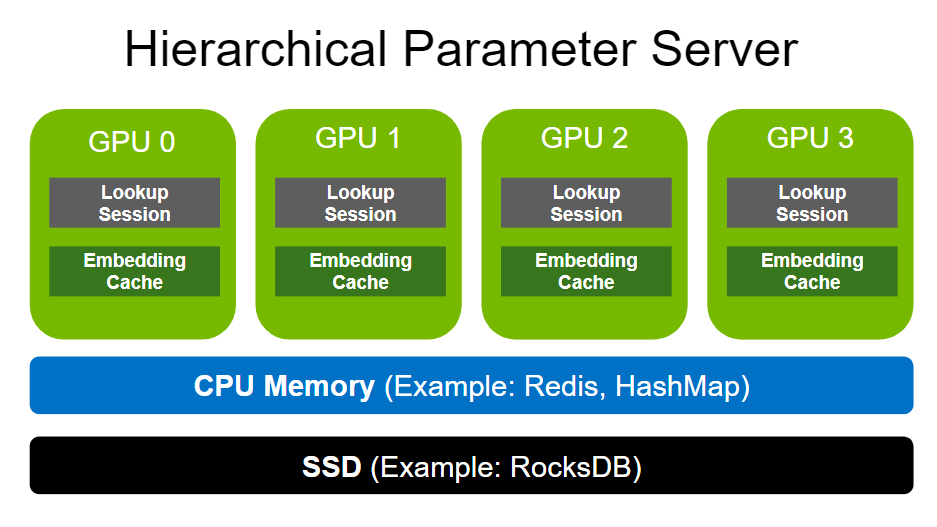
A high-level illustration of the Hierarchical Parameter Server architecture including the GPU embedding cache, a CPU memory layer, and a SSD layer. 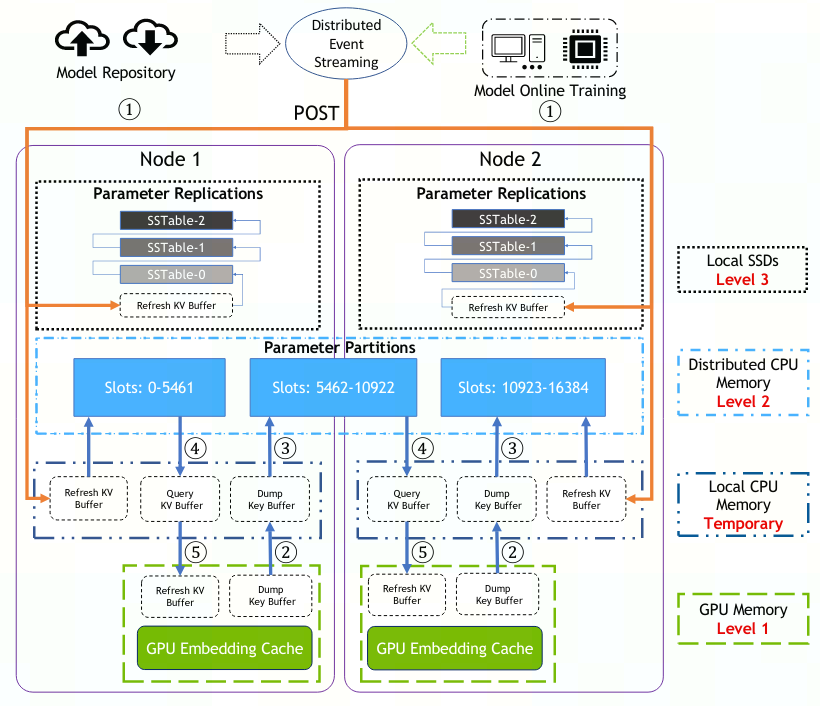
image-20221025110729581 - 管理消息流,获取更新应用与VDB和PDB
- Dump GPU嵌入缓存的key值到CPU 对应缓冲区中
- 从CPU内存和SSD中查找缓冲区中的key
- 复制对应的embedding到CPU的Query KV Buffer中
- GPU从缓冲区中读取数据与更新嵌入缓存
GPU嵌入缓存数据结构:
slots:基本存储单元,每个包含一组嵌入键,相关嵌入向量和访问计数器
slabs:将GPU warp线程数的slot打包为一个slab,warp中的每个线程负责一个slot,便可线性探测slabs,当发现了想要的key就可执行寄存器级的warp内通信(shuffle,ballot)来终止探测
slabsets: 多个slabs组合为一个slabset,线性探测时可先定位Slabset再定位某个具体Slab,不同Slabset之间就可避免冲突,增大并行性。每个warp在插入和查询时独占整个slabset,保证线程安全,而整个slabset总数远大于warp数,即便是互斥操作也不会明显卡顿
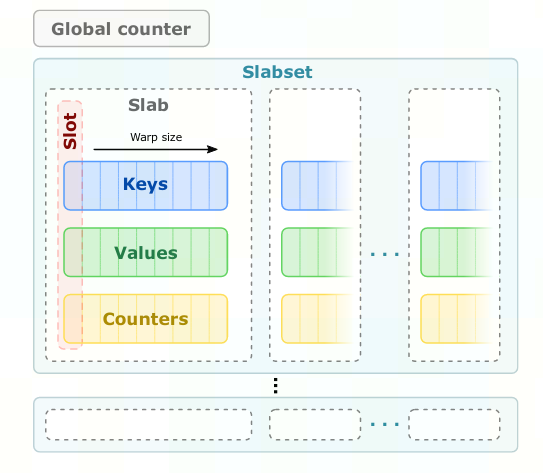
image-20221025113529836
GPU嵌入缓存API:所有API都异步执行CUDA kernels,因此能同时执行
Query:检索对应key的嵌入向量,未命中的key以列表形式返回,后续在level 2 CPU内存中继续获取

image-20221025144004296 Replace:即插入操作,若有空的slot,则插入embedding,若无,则遵从最近最少使用原则least recently used (LRU) 替换slot内的值
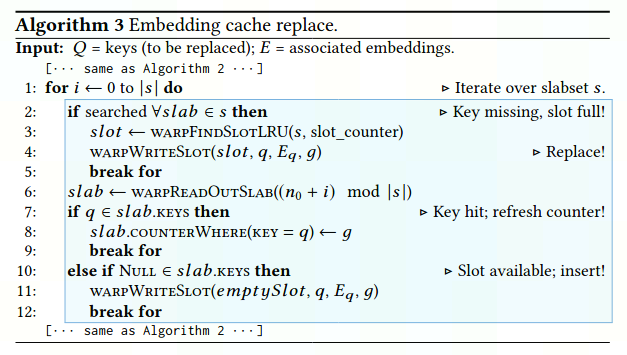
image-20221025144031116 Update:确定待更新key和已缓存key的交集,再替换对应嵌入向量

image-20221025144057260 Dump:输出当前在缓存中的keys
嵌入缓存插入:在GPU嵌入缓存中查找失败时,将触发level 2的CPU内存或level 3的SSD执行嵌入缓存插入操作
同步插入:缓存命中率低于定义的阈值时,阻塞其余部分,直到获取所需embedding(用于初始化和模型更新)
异步插入:缓存命中率高于定义的阈值时,立即获取缺失值,而插入GPU缓存操作异步执行供未来使用,确保高命中率(惰性插入机制)
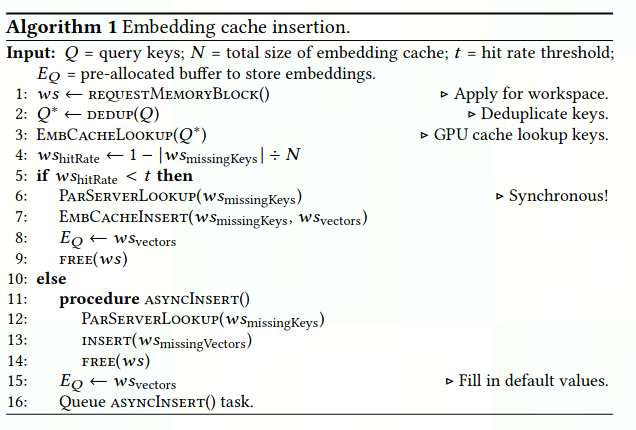
image-20221025150554697
在线模型更新:
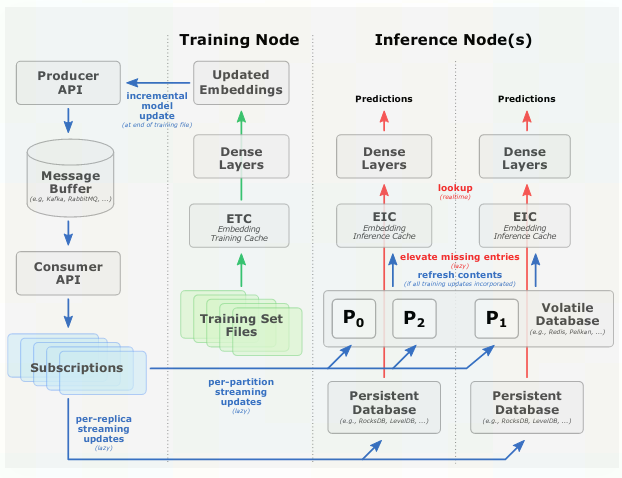
image-20221025155124162 - 因为这是模型的更新过程而不是embedding的查询过程,如果是像查询过程那样从PDB获取embedding来更新VDB,则还存在查询的开销,且负载都集中于PDB(既要自身更新,又要负载上层VDB的更新),相对于VDB,PDB相关操作速度更慢,所需时间开销更大
CPU内存和SSD数据库更新:
模型训练是资源密集型的,训练()和推理()使用不同节点进行,训练集被分为多个文件顺序加载到缓存中执行训练。
在线更新机制为辅助过程(),可随时启停,且更新过程无需停机,因此可实现持续性模型更新
当训练节点训练得到新的模型参数后,将会调用生产者API将更新dump到消息缓冲区(可使用Kafka实现),而推理节点可调用消费者API订阅消息队列获取更新(保证更新有序且完整,保证最终一致性)
在线更新会增加开销,但可通过lazy更新方式使用后台进程更新(可限制更新频率与获取速度),虽然lazy策略会带来模型更新过程中稍微不一致,但在实践中发现学习率在模型retraining过程中非常小,只要optimization足够平滑就不会带来预测性能下降。
GPU嵌入缓存更新:
- 不像VDB和PDB那样直接从Kafka获取更新,而是定期轮询VDB、PDB更新(直接从Kafka更新会产生难以预测的GPU负载峰值,可能缩短响应时间)
2.3.3 Sparse Operation Kit (SOK)
用于提供HugeCTR对稀疏模型训练的GPU加速op的python包,能在tensorflow中使用,并能兼容horovod和tensorflow的分布式策略
SOK训练的数据并行(DP)-模型并行(MP)-数据并行(DP)流程:
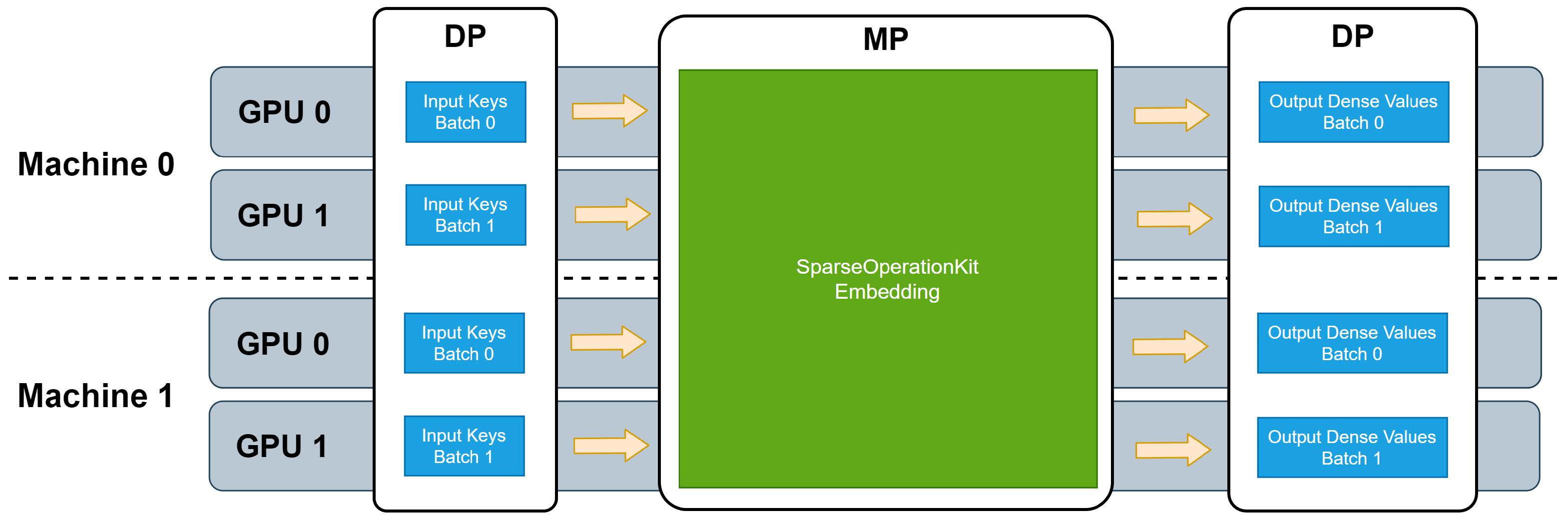
img 输入调度(DP→ MP)
将数据并行地输入,按照其求余 GPU 数量的结果,分配到了不同对应的 GPU 上,完成了 input key 从数据并行到模型并行的转化。虽然用户往每个 GPU 上输入的都可以是 embedding table 里的任何一个 key,但是经过上述的转化过程后,每个 GPU 上则只需要处理 embedding table 里 1/GPU_NUMBER 的 lookup
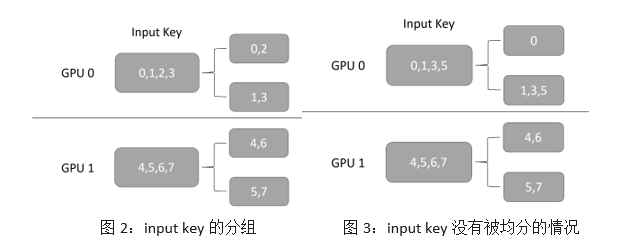
第一步:对每个 GPU 接收到的数据并行的 category key,按照 key 求余 GPU 的数量计算出其对应的 GPU ID,并分成和 GPU 数量相同的组;同时计算出每组内有多少 key。例如图 2 中,GPU 的总数为 2,GPU 0 获取的输入为[0, 1, 2, 3],根据前面所讲的规则,它将会被分成[0, 2], [1, 3]两组。注意,在这一步,我们还会为每个分组产生一个 order 信息,用于 output dispacher 的重排序。
第二步:通过 NCCL 交换各个 GPU 上每组 key 的数量。由于每个 GPU 获取的输入,按照 key 求余 GPU 数量不一定能够均分,如图 3 所示,提前在各个 GPU 上交换 key 的总数,可以在后面交换 key 的时候减少通信量。
第三步:使用 NCCL,在各个 GPU 间按照 GPU ID 交换前面分好的各组 key
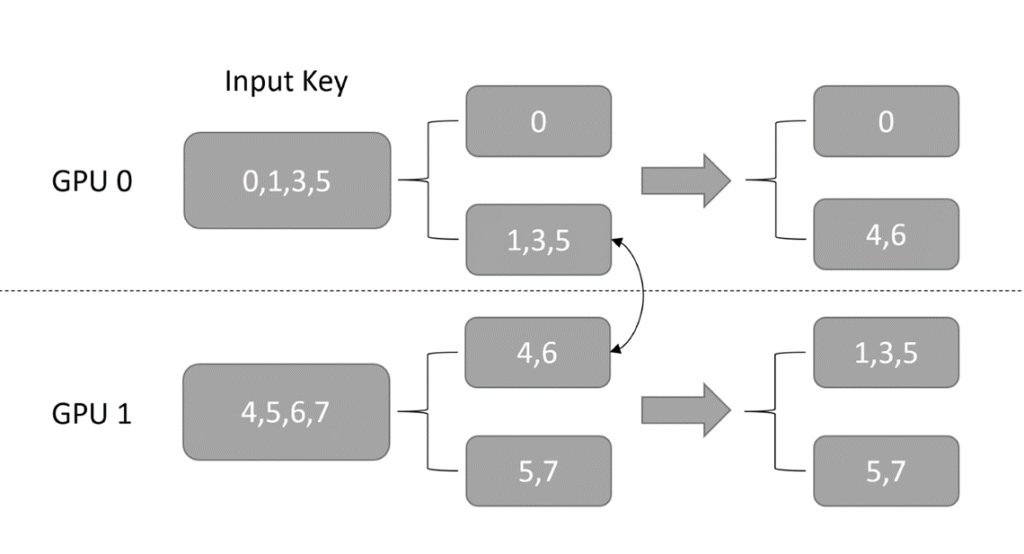
第四步:对交换后的所有 key 除以 GPU 总数,这一步是为了让每个 GPU 上的 key的数值范围都小于 embedding table size 整除 GPU 的数量,保证后续在每个 worker 上执行 lookup 时不会越界
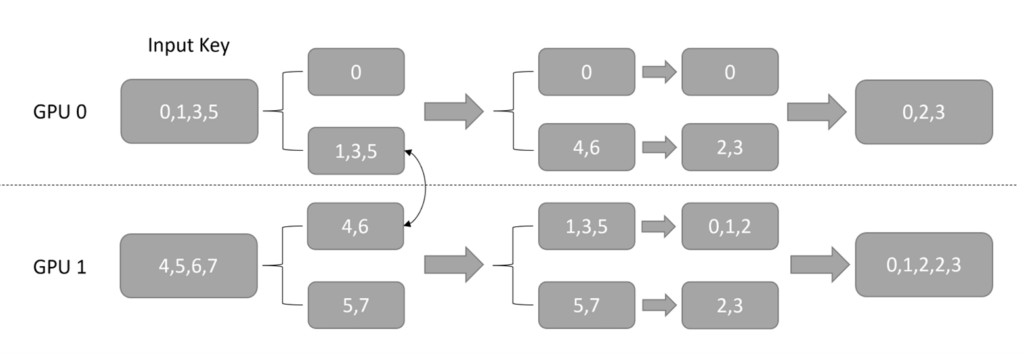
img
查表(Lookup)
- 使用输入调度输出的key在本地嵌入表中查询对应的嵌入向量
- 图中 Global Index 代表每个 embedding vector 在实际的 embedding table 中对应的 key,而 Index 则是当前 GPU 的“部分”embedding table 中的 key
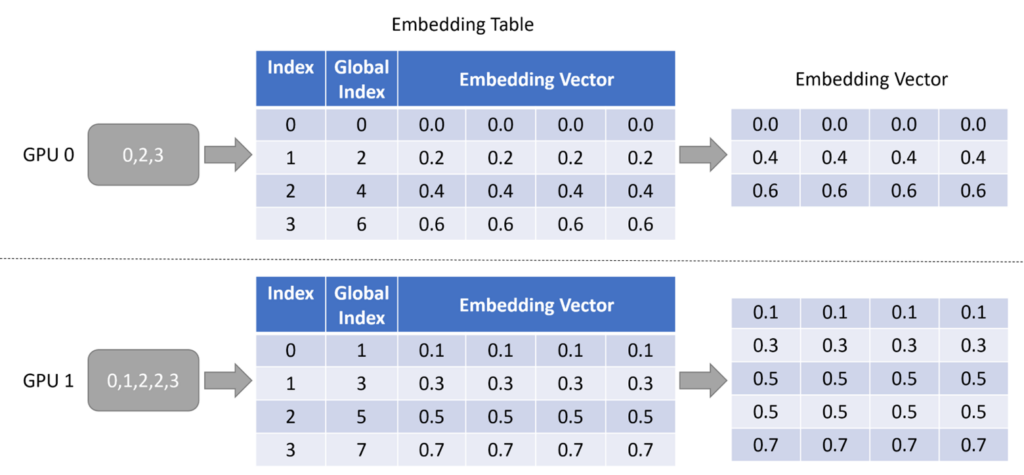
img
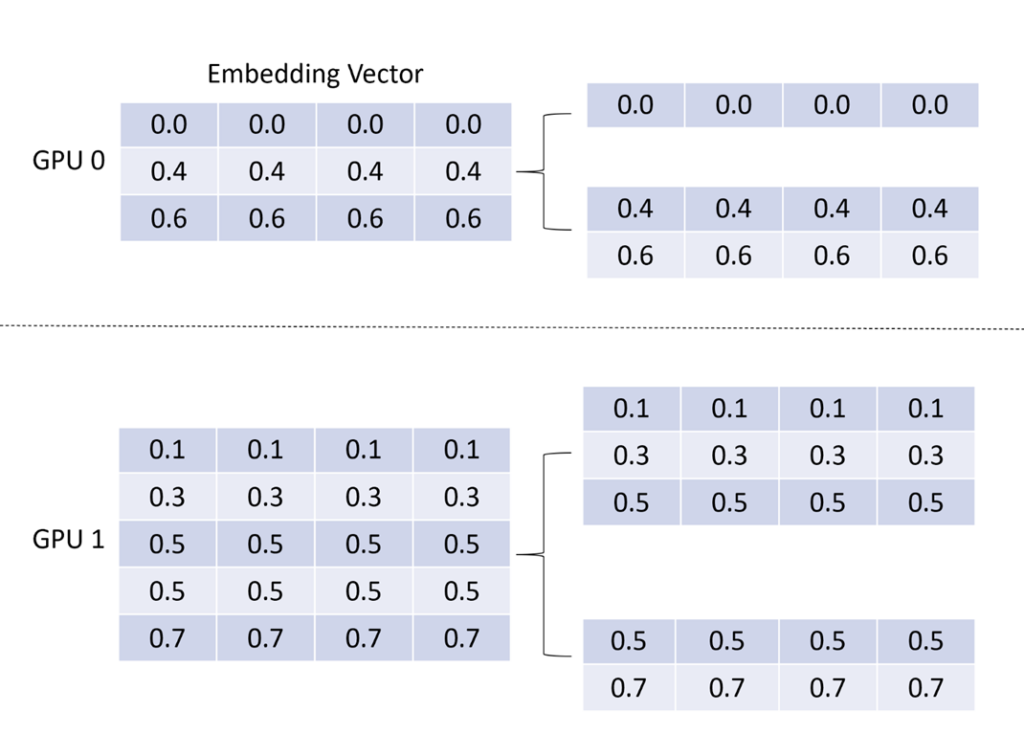
输出调度(MP→ DP)
- 将 embedding vector 按照和 input dispatcher 相同的路径、相反的方向将 embedding vector 返回给各个 GPU,让模型并行的 lookup 结果重新变成数据并行
- 第一步:复用 input dispatcher 中的分组信息,将 embedding vector 进行分组,如图 7 所示。
img - 第二步:通过 NCCL 将 embedding vector 按 input dispatcher 的路径返还,如图 8 所示。
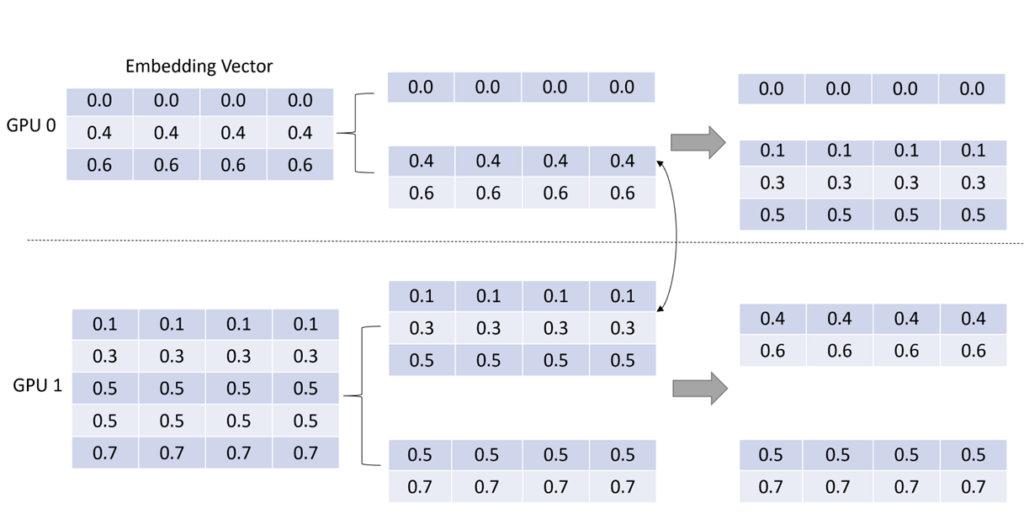
img - 第三步:复用 input dispatcher 第一步骤的结果,将 embedding vector 进行重排序,让其和输入的 key 顺序保持一致,如图 9 所示。
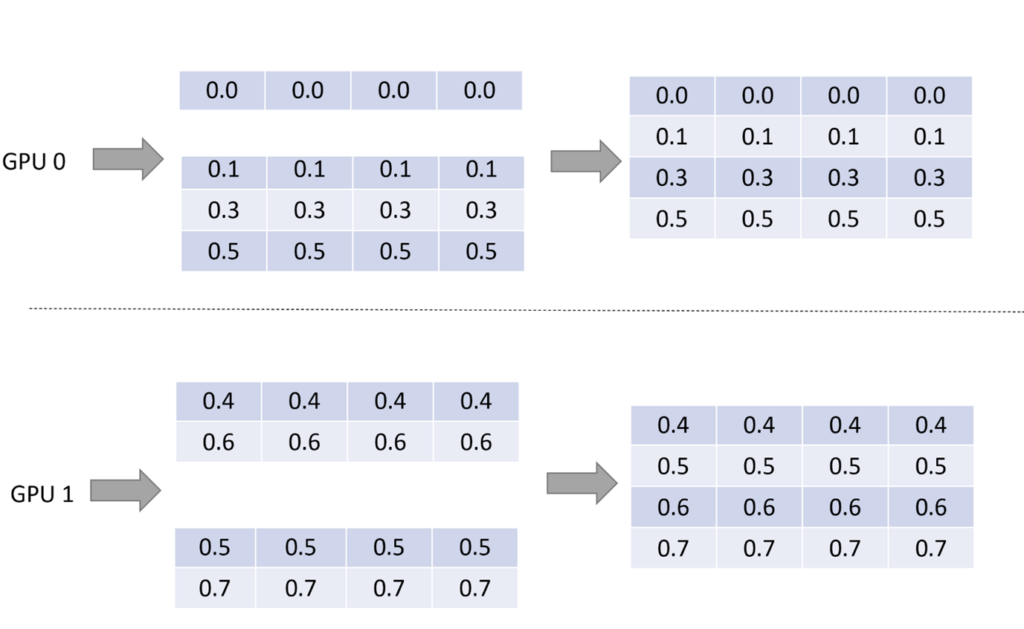
img - 可以看到, GPU 0 上输入的[0, 1, 3, 5],最终被转化为了[0.0, …], [0.1, …], [0.3, …], [0.5, …] 四个 embedding vector
- 虽然其中有 3 个 embedding vector 被存储在 GPU 1 上,但是以一种对用户透明的方式,在 GPU 0 上拿到了对应的 vector
- 在用户看来,就好像整个 embedding table 都存在 GPU 0 上一样
Backword:
- 与前向的工作流程和路径相同,需要做GPU之间的梯度交换,只是数据回传更新梯度的方向与前向相反
使用Steps:
- 定义模型结构: 使用 SOK 来搭建模型的时候,只需要将 TensorFlow 中的 Embedding Layer 替换为 SOK 对应的 API 即可

img
- 使用 Horovod 来定义 training loop: 使用 SOK 时,只需要对 Embedding Variables 和 Dense Variables 进行分别处理即可, Embedding Variables 部分由 SOK 管理,Dense Variables 由 TensorFlow 管理

img
- 使用 tf.distribute.MirroredStrategy 来定义 training loop:

img
- 执行训练:使用 SOK 与使用 TensorFlow 时所用代码一致

img
- 定义模型结构: 使用 SOK 来搭建模型的时候,只需要将 TensorFlow 中的 Embedding Layer 替换为 SOK 对应的 API 即可
3 安装HugeCTR
3.1 HugeCTR API
3.1.1 使用NGC容器
# 可根据需要挂载文件路径
# 此容器直接使用hugectr框架训练推理,未安装tensorflow等其他框架
docker run --name="hugectr-api" -v /data:/data --shm-size '64gb' --gpus all -it -p 8888:8888 -p 8797:8787 -p 8796:8786 --ipc=host --cap-add SYS_NICE nvcr.io/nvidia/merlin/merlin-hugectr:nightly /bin/bash
3.1.2 使用源码
Pending
3.2 HugeCTR SOK
3.2.1 使用NGC容器(tf2)
# 容器中已安装SOK
docker run nvcr.io/nvidia/merlin/merlin-tensorflow-training:22.04
3.2.2 使用pip(tf1或2, 目前tf1不推荐)
pip install sparse_operation_kit
3.2.3 使用源码
git clone https://github.com/NVIDIA-Merlin/HugeCTR.git
python setup.py install
python -c "import sparse_operation_kit as sok"
- :
SOK从1.1.0开始支持tf1.15,对应HCTR 3.3
SOK基于tf1.15只支持结合horovod使用
可使用最新NVIDIA Tensorflow镜像安装SOK:(:也可参考Merlin Dockerfile自定义镜像)
# https://catalog.ngc.nvidia.com/orgs/nvidia/containers/tensorflow/tags docker run -it --name="sok-tf1.15" --privileged --runtime=nvidia --net=host --gpus all --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 -v /data:/data -w / nvcr.io/nvidia/tensorflow:22.10-tf1-py3 /bin/bash- 基于此镜像只能用源码安装SOK,不能使用pip安装(用pip只能安装1.1.2版本,且会出现无法初始化问题)
# 升级cmake(至少3.17) apt-get autoremove cmake &&\ apt install build-essential libssl-dev &&\ wget https://cmake.org/files/v3.20/cmake-3.20.6-linux-x86_64.tar.gz &&\ tar xf cmake-3.20.6-linux-x86_64.tar.gz &&\ mv cmake-3.20.6-linux-x86_64 /opt/cmake-3.20.6 &&\ ln -sf /opt/cmake-3.20.6/bin/* /usr/bin vim ~/.bashrc # 添加下面一行内容 export PATH=$PATH:/opt/cmake-3.20.6/bin source ~/.bashrc # 安装相关依赖库 pip install scikit-build -i https://pypi.tuna.tsinghua.edu.cn/simple # 源码安装SOK git clone https://github.com/NVIDIA-Merlin/HugeCTR hugectr cd hugectr/sparse_operation_kit/ python setup.py install # 复制so库到/usr/local/lib下(此镜像下源码安装的bug) cp ./_skbuild/linux-x86_64-3.8/cmake-install/sparse_operation_kit/lib/*.so /usr/local/lib/ # 测试安装情况 python -c "import sparse_operation_kit as sok; print(sok.__version__)" # 执行测例(多卡测试默认为8卡,可在unit_test/test_scripts/tf1/script.sh脚本中修改 ... -np <gpu_number> ) export CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 bash ../unit_test/test_scripts/script.sh
参考资料:
项目:
文档 & paper:
Merlin HugeCTR‘s documentation
SparseOperationKit’s documentation
Merlin HugeCTR: GPU-accelerated Recommender System Training and Inference
A GPU-specialized Inference Parameter Server for Large-Scale Deep Recommendation Models
blogs:
[源码解析] NVIDIA HugeCTR,GPU版本参数服务器
扩展和加速大型深度学习推荐系统 – HugeCTR 系列第 1 部分
使用 Merlin HugeCTR 的 Python API 训练大型深度学习推荐模型 – HugeCTR 系列第 2 部分
Merlin HugeCTR Sparse Operation Kit 系列之一
Merlin HugeCTR Sparse Operation Kit 系列之二
Introducing NVIDIA Merlin HugeCTR: A Training Framework Dedicated to Recommender Systems
Using Neural Networks for Your Recommender System
性能数据来源:
GPU 计算专家团队 | HugeCTR :英伟达点击率预估训练框架原型开源
使用 HugeCTR TensorFlow 嵌入插件加速嵌入
Introducing NVIDIA Merlin HugeCTR: A Training Framework Dedicated to Recommender Systems