

CUDA学习笔记
CUDA学习笔记
0 目标
- 快速掌握
CUDA编程的大致方式 - 了解
CUDA软硬件组织架构与关系 - 了解如何查找文档
1 介绍
1.1 架构
CUDA (Compute Unified Device Architecture):统一计算设备架构,在 GPU 上发布的一个新的硬件和软件架构,它不需要映射到一个图形 API 便可在 GPU 上管理和进行并行数据计算
CPU、GPU架构对比:GPU 被设计用于高密度和并行计算,更确切地说是用于图形渲染,因此更多的晶体管被投入到数据处理而不是数据缓存和流量控制
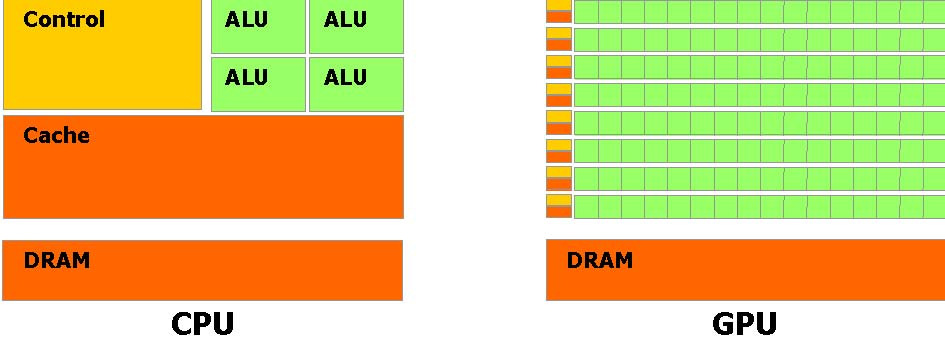
CUDA软件堆栈:CUDA 软件堆栈由几层组成:一个硬件驱动程序,一个应用程序编程接口(API)和它的Runtime, 还有二个高级的通用数学库,CUFFT 和CUBLAS
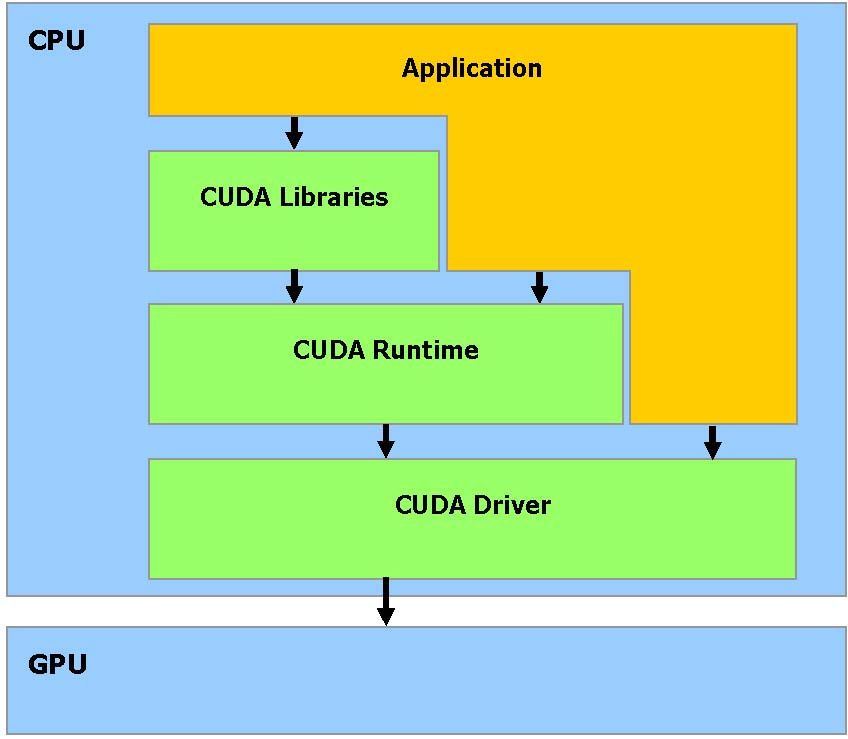
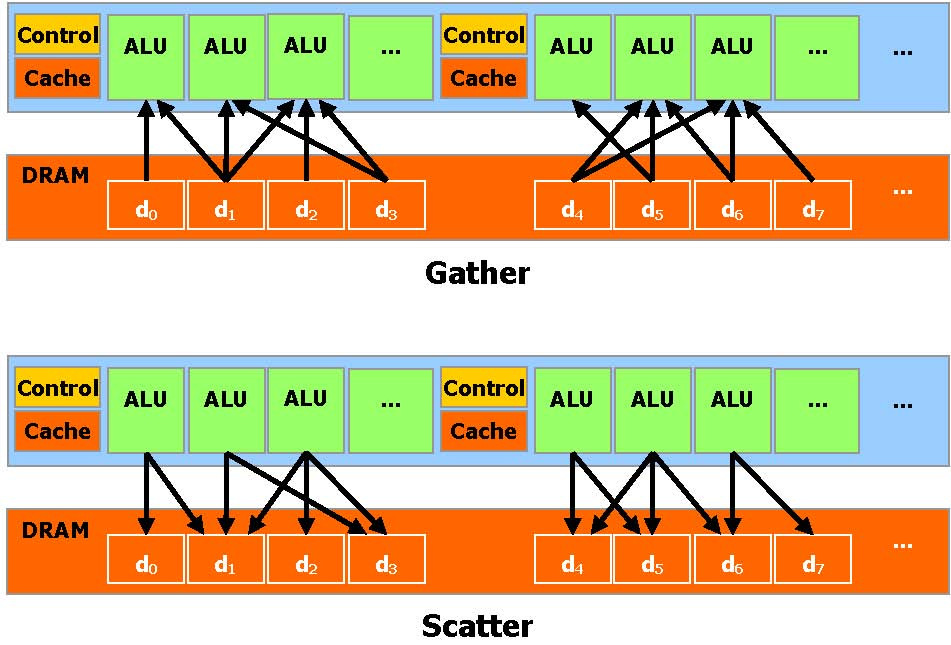
CUDA内存操作:CUDA 提供一般 DRAM 内存寻址方式: Gather 和 Scatter内存操作,它可以在 DRAM的任何区域进行读写数据的操作
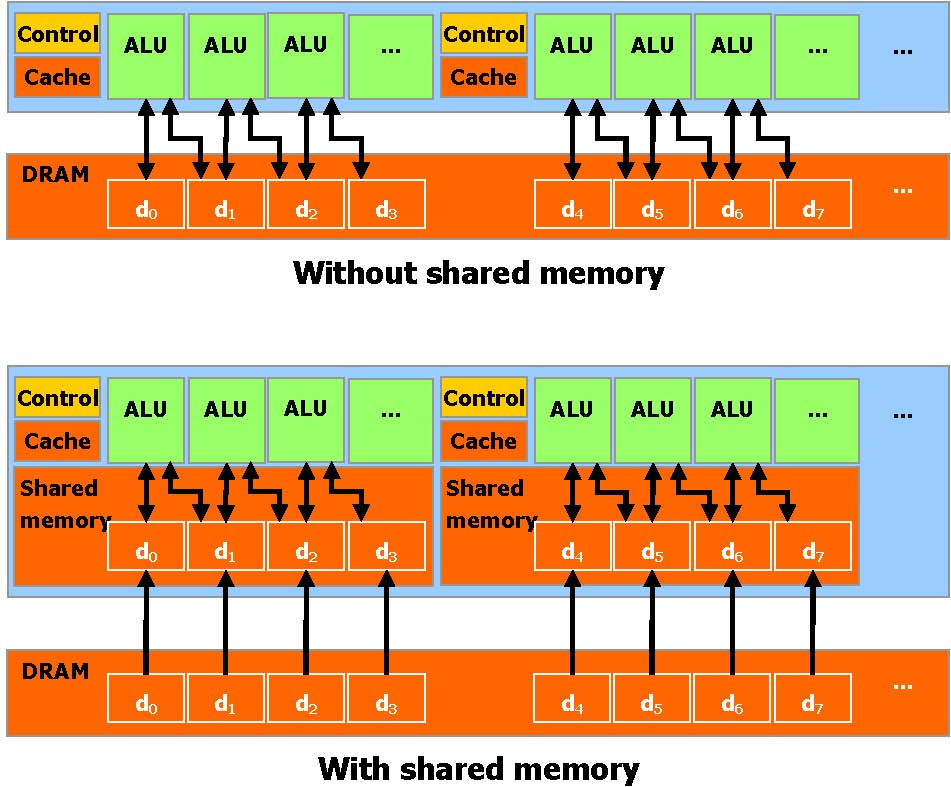
允许并行数据缓冲或者在 On-chip 内存共享使数据更接近ALU,可以进行快速的常规读写存取,在线程之间共享数据。应用程序可以最小化数据到 DRAM 的 overfetch 和 round-trips, 从而减少对 DRAM 内存带宽的依赖
1.2 编程模型
Kernel:一个被执行许多次不同数据的应用程序部分,可以被分离成为一个有很多不同线程在设备上执行的函数,最终被编译成设备的指令集
DMA:主机和设备使用它们自己的 DRAM ,主机内存和设备内存。并可以通过利用设备高性能直接内存存取 (
DMA)的引擎(API)从一个DRAM复制数据到其他DRAM线程批处理:线程批处理就是执行一个被组织成许多线程块的
Kernel,主机发送一个连续的kernel调用到设备。每个kernel作为一个由线程块组成的批处理线程来执行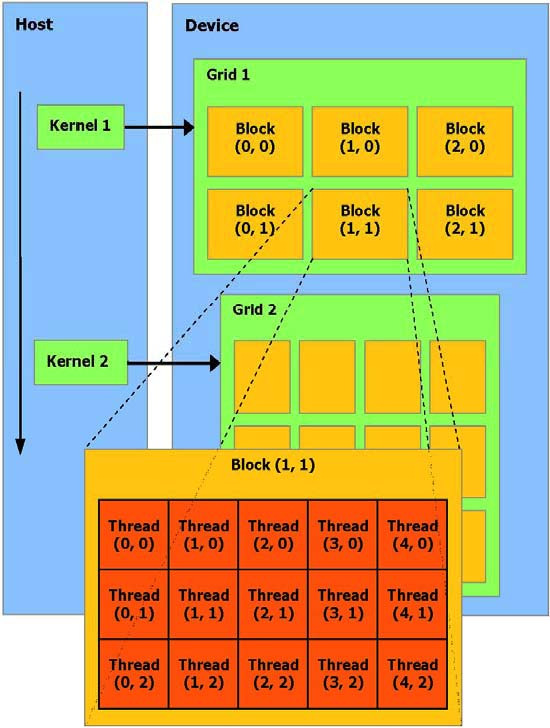
Block:包含多个线程,线程间共享数据,可在
Kernel中指定同步点,一个块里的线程被挂起直到它们所有都到达同步点,每个线程拥有Block内的Thread IDGrid:执行同一个
Kernel的块可以合成为一个Grid,同一个Grid中的不同Block中的线程不能通讯和同步,每个Block有对应的Block ID
1.3 内存模型
线程允许访问的内存空间:
- 读写每条线程的
寄存器 - 读写每条线程的
本地内存 - 读写每个
Block的共享内存 - 读写每个
Grid的全局内存 - 只读每个
Grid的常量内存 - 只读每个
Grid的纹理内存
- 读写每条线程的
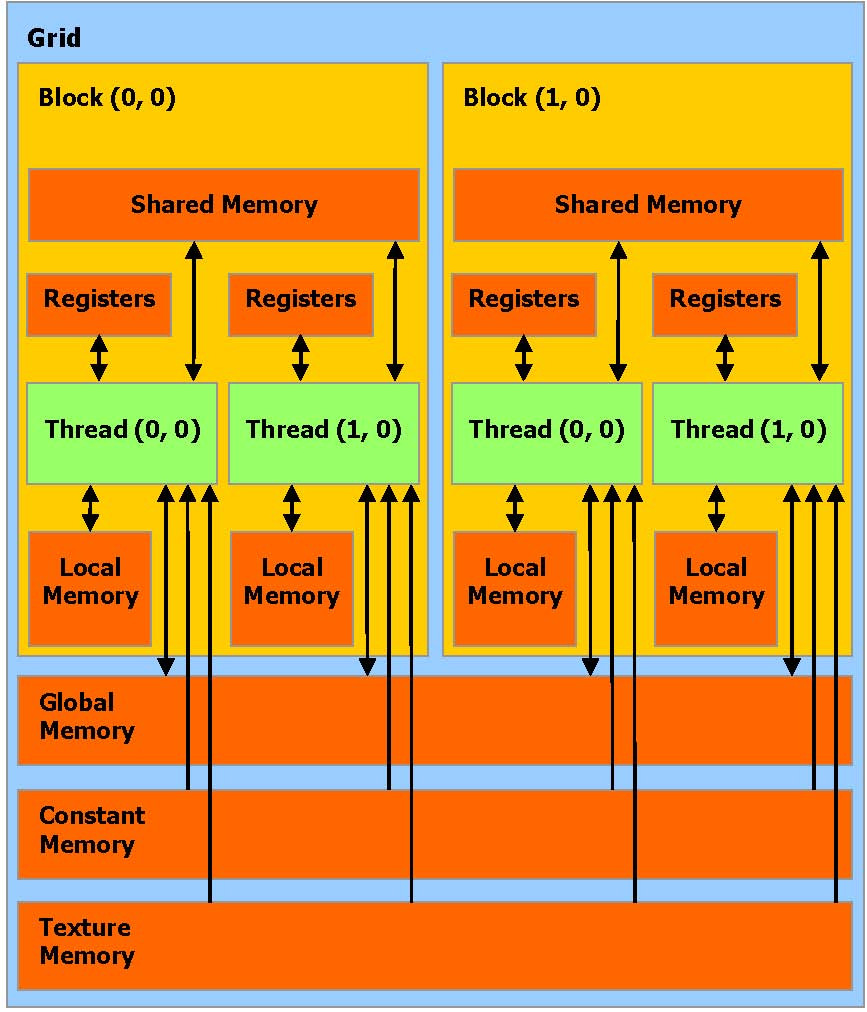
image-20221009172516961 全局,常量,和纹理内存空间可以通过主机或者同一应用程序持续的通过 kernel 调用来完成读取或写入
全局,常量,和纹理内存空间对不同内存的用法加以优化。纹理内存同样提供不同的寻址模式,也为一些特殊的数据格式进行数据过滤
1.4 硬件实现
- SIMD:单指令多数据,在给定时钟周期内,多处理器的每个处理器执行同一指令,操作不同数据,并行数据缓存或共享内存,被所有处理器共享实现内存空间共享,一个
Block只被一个多处理器处理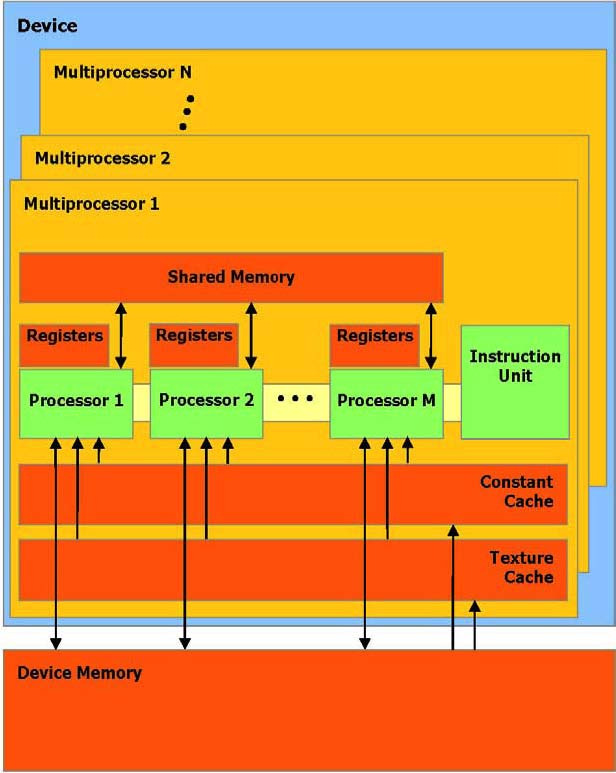
- Active:被一个多处理器执行的
Block,被称作active - Warp:每个
active被划分为多个SIMD方式的线程组,每一组称为一个warp,每个warp大小相同,线程调度程序周期性地从一个warp切换到另一个warp
2 API
- C语言扩展:
- 函数类型限定:指定函数执行的位置和调用位置
__device__: 设备上执行,仅可从设备调用__global__: 设备上执行,仅可从主机调用__host__: 主机上执行,仅可从主机调用
- 变量类型限定:指定设备上变量的内存位置
__device__:驻留在设备__constant__: 驻留在常量内存空间__shared__: 驻留在线程块的共享内存空间中- 只能通过设备代码中的
__device__,__shared__或__constant__变量来获取地址。__device__或__constant__变量的地址只能通过主机代码获得,cudaGetSymbolAddress()
- 在设备上执行的方式配置、指定
Grid和Block的维数,Block和Thread的ID- 所有
__global__函数的调用必须指定执行配置,执行配置定义了通常在设备执行的函数的Grid和Block的维数 - Dg:
dim3类型,指定Grid维数,Dg.x * Dg.y等于被发送Block的数量 - Db:
dim3类型,指定Block维数,Db.x * Db.y * Db.z等于每个Block的线程数 - Ns:
size_t类型,指定共享内存大小,可被任何外部数组变量使用,默认为0,可选参数 - S:
cudaStream_t类型,指定相关stream,默认为0,可选参数 - 示例:
- 声明:
__global__ void Func(float* parameter); - 调用:
Func<<< Dg, Db, Ns >>>(parameter);
- 声明:
- 所有
- 函数类型限定:指定函数执行的位置和调用位置
- 内置变量:
- gridDim:
dim3类型,指定Grid维数 - blockIdx:
uint3类型,指定Block ID - blockDim:
dim3类型,指定Block维数 - threadIdx:
uint3类型,指定Thread ID - 内置变量不允许取得任何地址且不允许赋值到任何内置变量
- gridDim:
- 每个包含CUDA 语言扩展的源文件必须通过CUDA 编译器
nvcc编译