

cuCollections性能测试
大约 14 分钟
cuCollections性能测试
0. 测试目标
- cucollection性能分析(测试在负载因子为0.8/0.9时的性能,以及空载时的插入性能,吞吐量,带宽 etc)key为64bit int,数据使用均匀分布
- [x] 阅读benchmark代码,修改benchmark中的参数,测试不同负载因子下的性能( dynamic, static)
- [x] 弄清example中的示例,基本用法,可参考test
- [x] 根据所需测试性能参数修改benchmark测试
1. 环境配置
测试环境:
IP Address x.x.x.x OS Ubuntu 18.04 LTS GPU 8xA100-40G / 8x Tesla V100-PCIE-32GB Interconnectivity PCIe Container NGC Pytorch 21.09-py3 / NGC Tensorflow 22.10-tf1-py3 pytorch:
# https://docs.nvidia.com/deeplearning/frameworks/pytorch-release-notes/rel_21-09.html#rel_21-09 docker run -it --name="cucollection-pt21.09" --privileged --net=host --gpus all --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 -v /data:/data -w / nvcr.io/nvidia/pytorch:21.09-py3 /bin/bash # 安装cmake(至少3.23)(原来的cmake是conda内安装的) wget https://cmake.org/files/v3.23/cmake-3.23.5-linux-x86_64.tar.gz &&\ tar xf cmake-3.23.5-linux-x86_64.tar.gz &&\ mv cmake-3.23.5-linux-x86_64 /opt/cmake-3.23.5 &&\ ln -sf /opt/cmake-3.23.5/bin/* /usr/bin vim ~/.bashrc # 添加下面一行内容 export PATH=$PATH:/opt/cmake-3.23.5/bin source ~/.bashrc # pull repository git clone https://github.com/NVIDIA/cuCollections.git # build cucollections cd cuCollections mkdir build cd build /opt/cmake-3.23.5/bin/cmake .. maketensorflow:
# https://catalog.ngc.nvidia.com/orgs/nvidia/containers/tensorflow/tags docker run -it --name="cucollection-tf1.15" --privileged --runtime=nvidia --net=host --gpus all --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 -v /data:/data -w / nvcr.io/nvidia/tensorflow:22.10-tf1-py3 /bin/bash docker run -it --name="cucollection-tf1.15" --privileged --runtime=nvidia --net=host --gpus all --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 -v /data:/data -w / nvcr.io/nvidia/tensorflow:22.09-tf1-py3 /bin/bash # 升级cmake(至少3.23) apt-get autoremove cmake &&\ apt install build-essential libssl-dev &&\ wget https://cmake.org/files/v3.23/cmake-3.23.5-linux-x86_64.tar.gz &&\ tar xf cmake-3.23.5-linux-x86_64.tar.gz &&\ mv cmake-3.23.5-linux-x86_64 /opt/cmake-3.23.5 &&\ ln -sf /opt/cmake-3.23.5/bin/* /usr/bin vim ~/.bashrc # 添加下面一行内容 export PATH=$PATH:/opt/cmake-3.23.5/bin source ~/.bashrc # pull repository git clone https://github.com/NVIDIA/cuCollections.git # build cucollections(cmake失败时可不删除build文件夹重新再执行一次cmake ..) cd cuCollections &&/ mkdir build &&/ cd build &&/ cmake .. &&/ make
2. Benchmark
修改benchmark内容用于测试:
// ./cuCollections/benchmarks/hash_table/static_map_bench.cu /* * Copyright (c) 2020-2022, NVIDIA CORPORATION. * * Licensed under the Apache License, Version 2.0 (the "License"); * you may not use this file except in compliance with the License. * You may obtain a copy of the License at * * http://www.apache.org/licenses/LICENSE-2.0 * * Unless required by applicable law or agreed to in writing, software * distributed under the License is distributed on an "AS IS" BASIS, * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. * See the License for the specific language governing permissions and * limitations under the License. */ #include <cuco/static_map.cuh> #include <thrust/device_vector.h> #include <thrust/for_each.h> #include <benchmark/benchmark.h> #include <fstream> #include <random> enum class dist_type { UNIQUE, UNIFORM, GAUSSIAN }; template <dist_type Dist, typename Key, typename OutputIt> static void generate_keys(OutputIt output_begin, OutputIt output_end) { auto num_keys = std::distance(output_begin, output_end); std::random_device rd; std::mt19937 gen{rd()}; switch (Dist) { case dist_type::UNIQUE: for (auto i = 0; i < num_keys; ++i) { output_begin[i] = i; } break; case dist_type::UNIFORM: for (auto i = 0; i < num_keys; ++i) { output_begin[i] = std::abs(static_cast<Key>(gen())); } break; case dist_type::GAUSSIAN: std::normal_distribution<> dg{1e9, 1e7}; for (auto i = 0; i < num_keys; ++i) { output_begin[i] = std::abs(static_cast<Key>(dg(gen))); } break; } } /** * @brief Generates input sizes and hash table occupancies * */ static void generate_size_and_occupancy(benchmark::internal::Benchmark* b) { // for (auto size = 100'000'000; size <= 100'000'000; size *= 10) { // for (auto occupancy = 10; occupancy <= 90; occupancy += 40) { // b->Args({size, occupancy}); // } // } b->Args({80'000'000, 80}); b->Args({90'000'000, 90}); } template <typename Key, typename Value, dist_type Dist> static void BM_static_map_insert(::benchmark::State& state) { using map_type = cuco::static_map<Key, Value>; std::size_t num_keys = state.range(0); float occupancy = state.range(1) / float{100}; std::size_t size = num_keys / occupancy; // std::cout<<"num_keys:"<<num_keys<<" occupancy:"<<occupancy<<" size:"<<size<<std::endl; std::vector<Key> h_keys(num_keys); std::vector<cuco::pair_type<Key, Value>> h_pairs(num_keys); generate_keys<Dist, Key>(h_keys.begin(), h_keys.end()); for (std::size_t i = 0; i < num_keys; ++i) { Key key = h_keys[i]; Value val = h_keys[i]; h_pairs[i].first = key; h_pairs[i].second = val; } thrust::device_vector<cuco::pair_type<Key, Value>> d_pairs(h_pairs); thrust::device_vector<Key> d_keys(h_keys); for (auto _ : state) { map_type map{size, cuco::sentinel::empty_key<Key>{-1}, cuco::sentinel::empty_value<Value>{-1}}; cudaEvent_t start, stop; cudaEventCreate(&start); cudaEventCreate(&stop); cudaEventRecord(start); map.insert(d_pairs.begin(), d_pairs.end()); cudaEventRecord(stop); cudaEventSynchronize(stop); float ms; cudaEventElapsedTime(&ms, start, stop); state.SetIterationTime(ms / 1000); // std::cout<<"size:"<<map.get_size()<<" capacity:"<<map.get_capacity()<<" load_factor:"<<map.get_load_factor()<<std::endl; } state.SetBytesProcessed((sizeof(Key) + sizeof(Value)) * int64_t(state.iterations()) * int64_t(state.range(0))); } template <typename Key, typename Value, dist_type Dist> static void BM_static_map_search_all(::benchmark::State& state) { using map_type = cuco::static_map<Key, Value>; std::size_t num_keys = state.range(0); float occupancy = state.range(1) / float{100}; std::size_t size = num_keys / occupancy; map_type map{size, cuco::sentinel::empty_key<Key>{-1}, cuco::sentinel::empty_value<Value>{-1}}; std::vector<Key> h_keys(num_keys); std::vector<Value> h_values(num_keys); std::vector<cuco::pair_type<Key, Value>> h_pairs(num_keys); std::vector<Value> h_results(num_keys); generate_keys<Dist, Key>(h_keys.begin(), h_keys.end()); for (std::size_t i = 0; i < num_keys; ++i) { Key key = h_keys[i]; Value val = h_keys[i]; h_pairs[i].first = key; h_pairs[i].second = val; } thrust::device_vector<Key> d_keys(h_keys); thrust::device_vector<Value> d_results(num_keys); thrust::device_vector<cuco::pair_type<Key, Value>> d_pairs(h_pairs); map.insert(d_pairs.begin(), d_pairs.end()); // std::cout<<"INIT: size:"<<map.get_size()<<" capacity:"<<map.get_capacity()<<" load_factor:"<<map.get_load_factor()<<std::endl; for (auto _ : state) { map.find(d_keys.begin(), d_keys.end(), d_results.begin()); // TODO: get rid of sync and rewrite the benchmark with `nvbench` // once https://github.com/NVIDIA/nvbench/pull/80 is merged cudaDeviceSynchronize(); // std::cout<<"size:"<<map.get_size()<<" capacity:"<<map.get_capacity()<<" load_factor:"<<map.get_load_factor()<<std::endl; } state.SetBytesProcessed((sizeof(Key) + sizeof(Value)) * int64_t(state.iterations()) * int64_t(state.range(0))); } template <typename Key, typename Value, dist_type Dist> static void BM_static_map_erase_all(::benchmark::State& state) { using map_type = cuco::static_map<Key, Value>; std::size_t num_keys = state.range(0); float occupancy = state.range(1) / float{100}; std::size_t size = num_keys / occupancy; // static map with erase support map_type map{size, cuco::sentinel::empty_key<Key>{-1}, cuco::sentinel::empty_value<Value>{-1}, cuco::sentinel::erased_key<Key>{-2}}; std::vector<Key> h_keys(num_keys); std::vector<Value> h_values(num_keys); std::vector<cuco::pair_type<Key, Value>> h_pairs(num_keys); std::vector<Value> h_results(num_keys); generate_keys<Dist, Key>(h_keys.begin(), h_keys.end()); for (std::size_t i = 0; i < num_keys; ++i) { Key key = h_keys[i]; Value val = h_keys[i]; h_pairs[i].first = key; h_pairs[i].second = val; } thrust::device_vector<Key> d_keys(h_keys); thrust::device_vector<bool> d_results(num_keys); thrust::device_vector<cuco::pair_type<Key, Value>> d_pairs(h_pairs); for (auto _ : state) { state.PauseTiming(); map.insert(d_pairs.begin(), d_pairs.end()); state.ResumeTiming(); map.erase(d_keys.begin(), d_keys.end()); } state.SetBytesProcessed((sizeof(Key) + sizeof(Value)) * int64_t(state.iterations()) * int64_t(state.range(0))); } BENCHMARK_TEMPLATE(BM_static_map_insert, int32_t, int32_t, dist_type::UNIFORM) ->Unit(benchmark::kMillisecond) ->Apply(generate_size_and_occupancy) ->UseManualTime(); BENCHMARK_TEMPLATE(BM_static_map_search_all, int32_t, int32_t, dist_type::UNIFORM) ->Unit(benchmark::kMillisecond) ->Apply(generate_size_and_occupancy); BENCHMARK_TEMPLATE(BM_static_map_insert, int64_t, int64_t, dist_type::UNIFORM) ->Unit(benchmark::kMillisecond) ->Apply(generate_size_and_occupancy) ->UseManualTime(); BENCHMARK_TEMPLATE(BM_static_map_search_all, int64_t, int64_t, dist_type::UNIFORM) ->Unit(benchmark::kMillisecond) ->Apply(generate_size_and_occupancy);// ./cuCollections/benchmarks/hash_table/dynamic_map_bench.cu /* * Copyright (c) 2020-2022, NVIDIA CORPORATION. * * Licensed under the Apache License, Version 2.0 (the "License"); * you may not use this file except in compliance with the License. * You may obtain a copy of the License at * * http://www.apache.org/licenses/LICENSE-2.0 * * Unless required by applicable law or agreed to in writing, software * distributed under the License is distributed on an "AS IS" BASIS, * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. * See the License for the specific language governing permissions and * limitations under the License. */ #include <synchronization.hpp> #include <cuco/dynamic_map.cuh> #include <thrust/device_vector.h> #include <benchmark/benchmark.h> #include <iostream> #include <random> enum class dist_type { UNIQUE, UNIFORM, GAUSSIAN }; template <dist_type Dist, typename Key, typename OutputIt> static void generate_keys(OutputIt output_begin, OutputIt output_end) { auto num_keys = std::distance(output_begin, output_end); std::random_device rd; std::mt19937 gen{rd()}; switch (Dist) { case dist_type::UNIQUE: for (auto i = 0; i < num_keys; ++i) { output_begin[i] = i; } break; case dist_type::UNIFORM: for (auto i = 0; i < num_keys; ++i) { output_begin[i] = std::abs(static_cast<Key>(gen())); } break; case dist_type::GAUSSIAN: std::normal_distribution<> dg{1e9, 1e7}; for (auto i = 0; i < num_keys; ++i) { output_begin[i] = std::abs(static_cast<Key>(dg(gen))); } break; } } static void gen_final_size(benchmark::internal::Benchmark* b) { // for (auto size = 10'000'000; size <= 150'000'000; size += 20'000'000) { // b->Args({size}); // } b->Args({150'000'000}); } template <typename Key, typename Value, dist_type Dist> static void BM_dynamic_insert(::benchmark::State& state) { using map_type = cuco::dynamic_map<Key, Value>; std::size_t num_keys = state.range(0); // std::cout<<num_keys<<std::endl; std::size_t initial_size = 1 << 27; // std::cout<<initial_size<<std::endl; std::vector<Key> h_keys(num_keys); std::vector<cuco::pair_type<Key, Value>> h_pairs(num_keys); generate_keys<Dist, Key>(h_keys.begin(), h_keys.end()); for (std::size_t i = 0; i < num_keys; ++i) { Key key = h_keys[i]; Value val = h_keys[i]; h_pairs[i].first = key; h_pairs[i].second = val; } thrust::device_vector<cuco::pair_type<Key, Value>> d_pairs(h_pairs); std::size_t batch_size = 1E6; for (auto _ : state) { map_type map{ initial_size, cuco::sentinel::empty_key<Key>{-1}, cuco::sentinel::empty_value<Value>{-1}}; { cuda_event_timer raii{state}; for (std::size_t i = 0; i < num_keys; i += batch_size) { map.insert(d_pairs.begin() + i, d_pairs.begin() + i + batch_size); // std::cout<<"size:"<<map.get_size()<<" capacity:"<<map.get_capacity()<<" load_factor:"<<map.get_load_factor()<<std::endl; } } } state.SetBytesProcessed((sizeof(Key) + sizeof(Value)) * int64_t(state.iterations()) * int64_t(state.range(0))); } template <typename Key, typename Value, dist_type Dist> static void BM_dynamic_search_all(::benchmark::State& state) { using map_type = cuco::dynamic_map<Key, Value>; std::size_t num_keys = state.range(0); std::size_t initial_size = 1 << 27; std::vector<Key> h_keys(num_keys); std::vector<cuco::pair_type<Key, Value>> h_pairs(num_keys); generate_keys<Dist, Key>(h_keys.begin(), h_keys.end()); for (std::size_t i = 0; i < num_keys; ++i) { Key key = h_keys[i]; Value val = h_keys[i]; h_pairs[i].first = key; h_pairs[i].second = val; } thrust::device_vector<Key> d_keys(h_keys); thrust::device_vector<cuco::pair_type<Key, Value>> d_pairs(h_pairs); thrust::device_vector<Value> d_results(num_keys); map_type map{ initial_size, cuco::sentinel::empty_key<Key>{-1}, cuco::sentinel::empty_value<Value>{-1}}; map.insert(d_pairs.begin(), d_pairs.end()); for (auto _ : state) { cuda_event_timer raii{state}; map.find(d_keys.begin(), d_keys.end(), d_results.begin()); } state.SetBytesProcessed((sizeof(Key) + sizeof(Value)) * int64_t(state.iterations()) * int64_t(state.range(0))); } BENCHMARK_TEMPLATE(BM_dynamic_insert, int32_t, int32_t, dist_type::UNIFORM) ->Unit(benchmark::kMillisecond) ->Apply(gen_final_size) ->UseManualTime(); BENCHMARK_TEMPLATE(BM_dynamic_search_all, int32_t, int32_t, dist_type::UNIFORM) ->Unit(benchmark::kMillisecond) ->Apply(gen_final_size) ->UseManualTime(); BENCHMARK_TEMPLATE(BM_dynamic_insert, int64_t, int64_t, dist_type::UNIFORM) ->Unit(benchmark::kMillisecond) ->Apply(gen_final_size) ->UseManualTime(); BENCHMARK_TEMPLATE(BM_dynamic_search_all, int64_t, int64_t, dist_type::UNIFORM) ->Unit(benchmark::kMillisecond) ->Apply(gen_final_size) ->UseManualTime();重新编译后测试benchmark
cd ./build make cd ./gbenchmarks ls # DYNAMIC_MAP_BENCH RBK_BENCH STATIC_MAP_BENCH ./DYNAMIC_MAP_BENCH ./STATIC_MAP_BENCH
3. 测试结果
static_map:
A100:
配置 load_factor OP GPU time CPU time OPS TPS Key: Int32
Value: Int32
Random: Uniformload_factor: 0.8
total_size:100000000BM_static_map_insert 17.8 ms 22.1 ms 4.494 B 33.402 GB/sec BM_static_map_search_all 11.1 ms 11.1 ms 7.207 B 53.623 GB/sec load_factor: 0.9
total_size:100000000BM_static_map_insert 24.8 ms 29.2 ms 3.629 B 27.054 GB/sec BM_static_map_search_all 16.8 ms 16.8 ms 5.357 B 39.987 GB/sec Key: Int64
Value: Int64
Random: Uniformload_factor: 0.8
total_size:100000000BM_static_map_insert 19.9 ms 25.9 ms 4.020 B 60.051 GB/sec BM_static_map_search_all 13.3 ms 13.3 ms 6.015 B 89.458 GB/sec load_factor: 0.9
total_size:100000000BM_static_map_insert 29.8 ms 36.5 ms 3.020 B 44.936 GB/sec BM_static_map_search_all 20.2 ms 20.2 ms 4.455 B 66.476 GB/sec V100:
配置 load_factor OP GPU time CPU time OPS TPS Key: Int32
Value: Int32
Random: Uniformload_factor: 0.8
total_size:100000000BM_static_map_insert 51.3 ms 56.0 ms 1.559 B 11.629 GB/sec BM_static_map_search_all 22.7 ms 22.7 ms 3.524 B 26.238 GB/sec load_factor: 0.9
total_size:100000000BM_static_map_insert 63.3 ms 68.1 ms 1.421 B 10.587 GB/sec BM_static_map_search_all 32.4 ms 32.4 ms 2.778 B 20.688 GB/sec Key: Int64
Value: Int64
Random: Uniformload_factor: 0.8
total_size:100000000BM_static_map_insert 58.7 ms 68.7 ms 1.363 B 20.296 GB/sec BM_static_map_search_all 26.8 ms 26.8 ms 2.985 B 44.415 GB/sec load_factor: 0.9
total_size:100000000BM_static_map_insert 76.6 ms 86.5 ms 1.175 B 17.506 GB/sec BM_static_map_search_all 40.5 ms 40.5 ms 2.222 B 33.102 GB/sec
dynamic_map: (从空载到插入对应大小key的性能,当超过load_factor设定值时将以放大2倍的形式扩容)
// 修改dynamic_map的load_factor方法: // ./cuCollections/include/cuco/detail/dynamic_map.inl namespace cuco { template <typename Key, typename Value, cuda::thread_scope Scope, typename Allocator> dynamic_map<Key, Value, Scope, Allocator>::dynamic_map( std::size_t initial_capacity, sentinel::empty_key<Key> empty_key_sentinel, sentinel::empty_value<Value> empty_value_sentinel, Allocator const& alloc) : empty_key_sentinel_(empty_key_sentinel.value), empty_value_sentinel_(empty_value_sentinel.value), size_(0), capacity_(initial_capacity), min_insert_size_(1E4), max_load_factor_(0.60), // 修改load_factor为0.8/0.9 alloc_{alloc} {...}A100:
配置 load_factor OP GPU time CPU time OPS TPS Key: Int32
Value: Int32
Random: Uniformload_factor: 0.8
key_size:150000000BM_static_map_insert 117.0 ms 125.0 ms 1.282 B 9.529 GB/sec BM_static_map_search_all 36.0 ms 36.0 ms 4.167 B 31.079 GB/sec load_factor: 0.9
key_size:150000000BM_static_map_insert 161 ms 169 ms 0.932 B 6.946 GB/sec BM_static_map_search_all 56.0 ms 56.0 ms 2.679 B 19.954 GB/sec Key: Int64
Value: Int64
Random: Uniformload_factor: 0.8
key_size:150000000BM_static_map_insert 162.0 ms 174.0 ms 0.926 B 13.815 GB/sec BM_static_map_search_all 48.6 ms 48.6 ms 3.086 B 46.037 GB/sec load_factor: 0.9
key_size:150000000BM_static_map_insert 210 ms 222 ms 0.714 B 10.632 GB/sec BM_static_map_search_all 81.6 ms 81.6 ms 1.838 B 27.404 GB/sec V100:
配置 load_factor OP GPU time CPU time OPS TPS Key: Int32
Value: Int32
Random: Uniformload_factor: 0.8
key_size:150000000BM_static_map_insert 152 ms 158 ms 0.987 B 7.370 GB/sec BM_static_map_search_all 63.5 ms 63.5 ms 2.362 B 17.610 GB/sec load_factor: 0.9
key_size:150000000BM_static_map_insert 216 ms 223 ms 0.694 B 5.173 GB/sec BM_static_map_search_all 92.8 ms 92.8 ms 1.616 B 12.049 GB/sec Key: Int64
Value: Int64
Random: Uniformload_factor: 0.8
key_size:150000000BM_static_map_insert 192 ms 206 ms 0.781 B 11.637 GB/sec BM_static_map_search_all 83.7 ms 83.7 ms 1.792 B 26.698 GB/sec load_factor: 0.9
key_size:150000000BM_static_map_insert 287 ms 299 ms 0.523 B 7.800 GB/sec BM_static_map_search_all 141 ms 141 ms 1.064 B 15.896 GB/sec
key: int64(均匀分布) value: 64 bytes(任意值)
每次插入3000000个数据,需要记录每轮插入数据的load_factor和throughput(Gpair/s)
e.g.
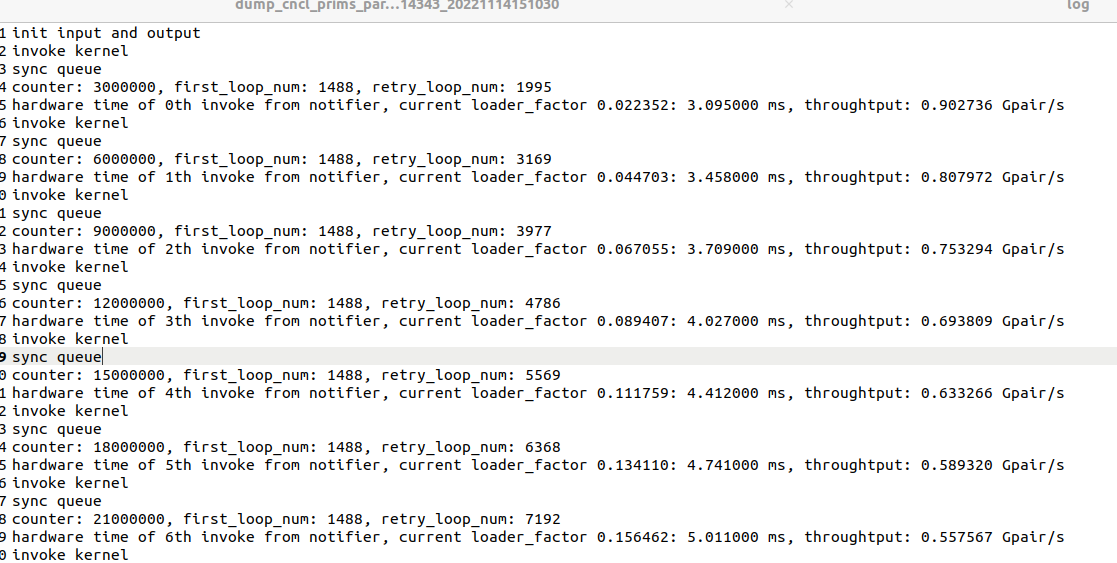
Gpair/s
#include <cuco/static_map.cuh>
#include <thrust/device_vector.h>
#include <thrust/for_each.h>
#include <thrust/iterator/counting_iterator.h>
#include <thrust/iterator/transform_iterator.h>
#include <thrust/logical.h>
#include <thrust/transform.h>
#include <benchmark/benchmark.h>
#include <fstream>
#include <random>
// User-defined value type
struct Embedding_64 {
int64_t data[8];
__host__ __device__ Embedding_64() {}
__host__ __device__ Embedding_64(int64_t x) : data{x} {}
__device__ bool operator == (Embedding_64 const& cmp)
{
return data[0] == cmp.data[0];
}
};
struct Embedding_128 {
int64_t data[16];
__host__ __device__ Embedding_128() {}
__host__ __device__ Embedding_128(int64_t x) : data{x} {}
__device__ bool operator == (Embedding_128 const& cmp)
{
return data[0] == cmp.data[0];
}
};
struct Embedding_512 {
int64_t data[64];
__host__ __device__ Embedding_512() {}
__host__ __device__ Embedding_512(int64_t x) : data{x} {}
__device__ bool operator == (Embedding_512 const& cmp)
{
return data[0] == cmp.data[0];
}
};
// Generate key with uniform distribution
template <typename Key, typename OutputIt>
static void generate_keys(OutputIt output_begin, OutputIt output_end)
{
auto num_keys = std::distance(output_begin, output_end);
std::random_device rd;
std::mt19937 gen{rd()};
for (auto i = 0; i < num_keys; ++i) {
output_begin[i] = std::abs(static_cast<Key>(gen()));
}
}
int main(void)
{
using Key = int64_t;
// using Value = int64_t;
using Value = Embedding_128;
using map_type = cuco::static_map<Key, Value>;
std::size_t num_keys = 95'000'000;
std::size_t size = 100'000'000;
std::vector<Key> h_keys(num_keys);
std::vector<cuco::pair_type<Key, Value>> h_pairs(num_keys);
generate_keys<Key>(h_keys.begin(), h_keys.end());
std::cout<<"Key_size:"<<sizeof(Key)<<" Value_size:"<<sizeof(Value)<<std::endl;
for (std::size_t i = 0; i < num_keys; ++i) {
Key key = h_keys[i];
Value val{i};
h_pairs[i].first = key;
h_pairs[i].second = val;
}
thrust::device_vector<cuco::pair_type<Key, Value>> d_pairs(h_pairs);
thrust::device_vector<Key> d_keys(h_keys);
map_type map{size, cuco::sentinel::empty_key<Key>{-1}, cuco::sentinel::empty_value<Value>{Value{-1}}};
int64_t last_loop_key_size = 0;
for(size_t i=0; i<num_keys/3'000'000; i+=1)
{
cudaEvent_t start, stop;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaEventRecord(start);
map.insert(d_pairs.begin()+i*3'000'000, d_pairs.begin()+(i+1)*3'000'000);
cudaEventRecord(stop);
cudaEventSynchronize(stop);
float time_ms;
cudaEventElapsedTime(&time_ms, start, stop);
std::cout<<"time: "<<time_ms<<"ms key_size: "<<map.get_size()<<" total_size: "<<map.get_capacity()<<" load_factor: "<<map.get_load_factor()<<" throughput: "<<(map.get_size()-last_loop_key_size)/time_ms/1'000'000<<"Gpair/s"<<std::endl;
last_loop_key_size = map.get_size();
}
/*---Check whether all keys are inside the hashtable---*/
// Reproduce inserted keys
auto insert_keys =
thrust::make_transform_iterator(thrust::make_counting_iterator<int32_t>(0),
[] __device__(auto i) { return int64_t{i}; });
thrust::device_vector<bool> contained(num_keys);
map.contains(
insert_keys, insert_keys + num_keys, contained.begin());
assert(
thrust::all_of(contained.begin(), contained.end(), [] __device__(auto const& b) { return b; }));
return 0;
}
insert 调用关系:
// 用户定义cu文件调用insert方法,传入所有待插入的键值对 map.insert(d_pairs.begin()+i*loop_step, d_pairs.begin()+(i+1)*loop_step);// ./cuCollections/include/cuco/detail/static_map.inl // 调用kernel函数 template <typename Key, typename Value, cuda::thread_scope Scope, typename Allocator> template <typename InputIt, typename Hash, typename KeyEqual> void static_map<Key, Value, Scope, Allocator>::insert( InputIt first, InputIt last, Hash hash, KeyEqual key_equal, cudaStream_t stream) { auto num_keys = std::distance(first, last); if (num_keys == 0) { return; } auto const block_size = 128; auto const stride = 1; auto const tile_size = 1; auto const grid_size = (tile_size * num_keys + stride * block_size - 1) / (stride * block_size); auto view = get_device_mutable_view(); // TODO: memset an atomic variable is unsafe static_assert(sizeof(std::size_t) == sizeof(atomic_ctr_type)); CUCO_CUDA_TRY(cudaMemsetAsync(num_successes_, 0, sizeof(atomic_ctr_type), stream)); std::size_t h_num_successes; detail::insert<block_size, tile_size><<<grid_size, block_size, 0, stream>>>( first, first + num_keys, num_successes_, view, hash, key_equal); CUCO_CUDA_TRY(cudaMemcpyAsync( &h_num_successes, num_successes_, sizeof(atomic_ctr_type), cudaMemcpyDeviceToHost, stream)); CUCO_CUDA_TRY(cudaStreamSynchronize(stream)); // stream sync to ensure h_num_successes is updated size_ += h_num_successes; }// ./cuCollections/include/cuco/detail/static_map_kernels.cuh // 使用Cooperative Group来取得更高的吞吐并在高load_factor下保持稳定 // 将所有待插入的kv按照tile_size划分与分配,并进行最终的插入成功次数计数 template <std::size_t block_size, uint32_t tile_size, typename InputIt, typename atomicT, typename viewT, typename Hash, typename KeyEqual> __global__ void insert( InputIt first, InputIt last, atomicT* num_successes, viewT view, Hash hash, KeyEqual key_equal) { typedef cub::BlockReduce<std::size_t, block_size> BlockReduce; __shared__ typename BlockReduce::TempStorage temp_storage; std::size_t thread_num_successes = 0; auto tile = cg::tiled_partition<tile_size>(cg::this_thread_block()); auto tid = block_size * blockIdx.x + threadIdx.x; auto it = first + tid / tile_size; while (it < last) { // force conversion to value_type typename viewT::value_type const insert_pair{*it}; if (view.insert(tile, insert_pair, hash, key_equal) && tile.thread_rank() == 0) { thread_num_successes++; } it += (gridDim.x * block_size) / tile_size; } // compute number of successfully inserted elements for each block // and atomically add to the grand total std::size_t block_num_successes = BlockReduce(temp_storage).Sum(thread_num_successes); if (threadIdx.x == 0) { *num_successes += block_num_successes; } }// cuCollections/include/cuco/detail/static_map.inl // 每个tile每次插入一对kv的具体实现 template <typename Key, typename Value, cuda::thread_scope Scope, typename Allocator> template <typename CG, typename Hash, typename KeyEqual> __device__ bool static_map<Key, Value, Scope, Allocator>::device_mutable_view::insert( CG const& g, value_type const& insert_pair, Hash hash, KeyEqual key_equal) noexcept { auto current_slot = initial_slot(g, insert_pair.first, hash); while (true) { key_type const existing_key = current_slot->first.load(cuda::std::memory_order_relaxed); // The user provide `key_equal` can never be used to compare against `empty_key_sentinel` as the // sentinel is not a valid key value. Therefore, first check for the sentinel auto const slot_is_available = detail::bitwise_compare(existing_key, this->get_empty_key_sentinel()) or detail::bitwise_compare(existing_key, this->get_erased_key_sentinel()); // if equal, return 1, means slot is avaliable // the key we are trying to insert is already in the map, so we return with failure to insert if (g.any(not slot_is_available and key_equal(existing_key, insert_pair.first))) { return false; } auto const window_contains_available = g.ballot(slot_is_available); // return 0 while no threads in g can get an avaliable slot // we found an empty slot, but not the key we are inserting, so this must // be an empty slot into which we can insert the key if (window_contains_available) { // the first lane in the group with an empty slot will attempt the insert insert_result status{insert_result::CONTINUE}; uint32_t src_lane = __ffs(window_contains_available) - 1; if (g.thread_rank() == src_lane) { // One single CAS operation if `value_type` is packable if constexpr (cuco::detail::is_packable<value_type>()) { status = packed_cas(current_slot, insert_pair, key_equal, existing_key); } // Otherwise, two back-to-back CAS operations else { #if (__CUDA_ARCH__ < 700) status = cas_dependent_write(current_slot, insert_pair, key_equal, existing_key); #else // 自定义embedding的value大小超过8B,使用b2b_cas分两次插入kv status = back_to_back_cas(current_slot, insert_pair, key_equal, existing_key); #endif } } uint32_t res_status = g.shfl(static_cast<uint32_t>(status), src_lane); status = static_cast<insert_result>(res_status); // successful insert if (status == insert_result::SUCCESS) { return true; } // duplicate present during insert if (status == insert_result::DUPLICATE) { return false; } // if we've gotten this far, a different key took our spot // before we could insert. We need to retry the insert on the // same window } // if there are no empty slots in the current window, // we move onto the next window else { // 当前window向后移 current_slot = next_slot(g, current_slot); } } }// cuCollections/include/cuco/detail/static_map.inl // 插入操作的cas,key和value分别实现原子操作插入 // 要么是成功插入返回SUCCESS,要么是当前window无空slot返回CONTINUE,要么是当前key已经在map中了返回DUPLICATE template <typename Key, typename Value, cuda::thread_scope Scope, typename Allocator> template <typename KeyEqual> __device__ static_map<Key, Value, Scope, Allocator>::device_mutable_view::insert_result static_map<Key, Value, Scope, Allocator>::device_mutable_view::back_to_back_cas( iterator current_slot, value_type const& insert_pair, KeyEqual key_equal, Key expected_key) noexcept { // back_to_back_cas(current_slot, insert_pair, key_equal, existing_key) using cuda::std::memory_order_relaxed; auto expected_value = this->get_empty_value_sentinel(); // Back-to-back CAS for 8B/8B key/value pairs auto& slot_key = current_slot->first; auto& slot_value = current_slot->second; bool key_success = slot_key.compare_exchange_strong(expected_key, insert_pair.first, memory_order_relaxed); bool value_success = slot_value.compare_exchange_strong(expected_value, insert_pair.second, memory_order_relaxed); if (key_success) { while (not value_success) { value_success = slot_value.compare_exchange_strong(expected_value = this->get_empty_value_sentinel(), insert_pair.second, memory_order_relaxed); } return insert_result::SUCCESS; } else if (value_success) { slot_value.store(this->get_empty_value_sentinel(), memory_order_relaxed); } // our key was already present in the slot, so our key is a duplicate if (key_equal(insert_pair.first, expected_key)) { return insert_result::DUPLICATE; } return insert_result::CONTINUE; }