

Torchrec调研
Torchrec调研
0.0 未迁移依赖库汇总
- torch
- torch.distributed._shard
- torch.fx._compatibility
- torch.distributed._composable
- torch.distributed.optim._apply_optimizer_in_backward
- torch.distributed.fsdp
- torch._C.distributed_c10d.ProcessGroupNCCL
- torch.distributed._composable.contract
- fbgemm-gpu
0.1 QA
- 参考资料:
- https://pytorch.org/torchrec/ (torchrec文档)
- https://github.com/facebookresearch/dlrm/tree/main/torchrec_dlrm (dlrm)
- https://blog.csdn.net/u013701860/article/details/51140762 (uvm)
- https://www.sohu.com/a/560275515_100093134(整体介绍)
- https://zhuanlan.zhihu.com/p/619060815(整体介绍)
- DMP(Distributed Model Parallel), EBC(Embedding Bag Collections), KJT(Keyed Jagged Tensor), Planner, Sharder等
- 主要是对模型并行,embedding切分方式以及自动制定分片计划,稀疏,量化等的实现
使用EBC数据结构存储embedding
使用fused ebc(见后续数据结构对比介绍)
支持动态表
- 动态表是cpu还是gpu实现的?
- CPU\GPU混合实现,torchrec早期版本不支持动态扩容,对超百亿规模模型无法支持,后续是微信团队开发动态表功能后22.9月整合进新版本(见介绍)
- 也类似于hugectr的gpu cache机制,cpu维护一个映射表,映射不同emb在gpu中的分布情况,将常用的emb放显存中,未命中的从ps内存捞,使用的驱逐策略比较有意思,结合了LRU和LFU
- dynamic emb目前是以torchrec_dynamic_embedding扩展库的形式整合进torchrec项目中的,在torchrec/contrib/dynamic_embedding下,需要单独编译;整合进torchrec/torchrec/csrc中的代码是从cotrib路径下迁过来的,添加了更多benchmarks和unittests,但是python api貌似还没开发完成,建议使用contrib路径下的源码安装扩展
- 驱逐策略
- 使用LRU和LFU混合的驱逐策略, 最后记录在队列中的内容被驱逐
- 频次使用指数位记录,5bits,概率算法,每次取频次位随机数,全为零是频次指数加一
- 时间使用27bits记录
- 频次位在时间位前,LFU优先级比LRU高(值越小说明使用的越少,则换出)
- 使用队列批量驱逐显存中的emb

evict_strategy
- 动态表是cpu还是gpu实现的?
支持多种embedding切分方式:
row-wise, column-wise, table-wise
及三种方式的混合
- 使用多种不同的分片方式的原因:
- 在实际场景中,不同特征的访问频率是不同的,呈现幂率分布
- 若只使用row-wise,则每个特征域对应的emb table将会分布到不同gpu上,由于特征的幂率分布,从不同gpu中获取emb vector的规模可能会不均衡,影响通信性能
- 而使用col-wise,则每找一个特征对应的emb vector都要从所有gpu中获取数据拼接成完整的数据,使通信量均衡
- 用户可根据业务场景自定义分片方式
- 使用多种不同的分片方式的原因:
- 实现了DMP,对网络sparse部分作模型并行,对dense部分作DDP
- pipline:支持数据读取、分发、训练流水
- torchrec.distributed.train_pipeline.TrainPipelineBase 使用两个流
- the current (default) stream: 执行前线反向优化计算
- self._memcpy_stream:执行input从host到GPU
- torchrec.distributed.train_pipeline.TrainPipelineSparseDist, 隐藏all2all延迟,同时保留前向/反向的训练顺序
- stage 3: forward, backward - uses default CUDA stream
- stage 2: ShardedModule.input_dist() - uses data_dist CUDA stream
- stage 1: device transfer - uses memcpy CUDA stream
- torchrec.distributed.train_pipeline.TrainPipelineBase 使用两个流
- 传统推荐系统的ps架构
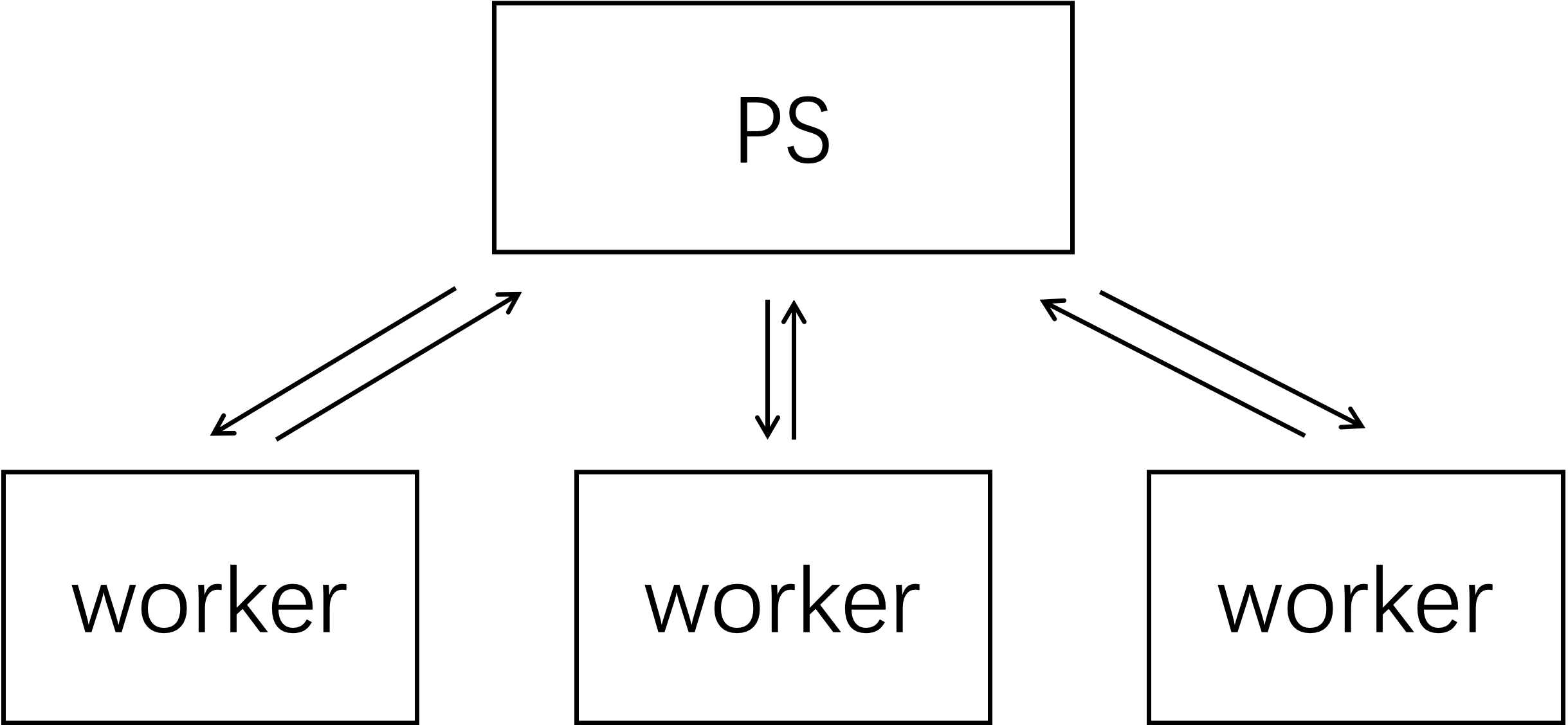
- 以cpu为中心,ps做kv存储,worker在每个iter从ps捞所需emb vector,前向反向后将更新后的特征推送回ps
- emb table在cpu上
- 训练过程需要等待通信,难以组成流水线,无法充分利用算力
- torchrec的ps架构
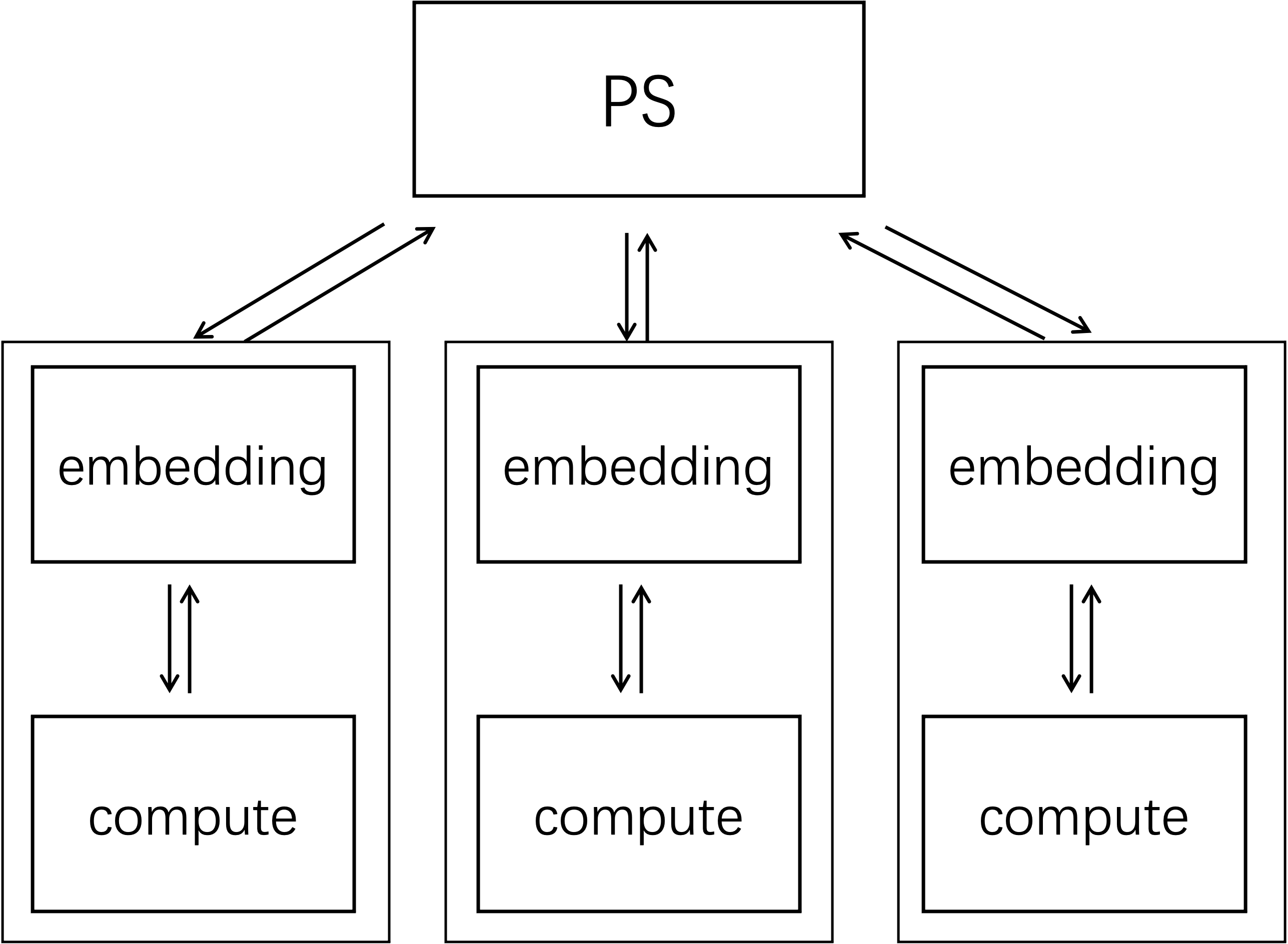
- 以gpu为中心,利用gpu间高带宽通信交换所需emb vector(数据、模型混合并行),能减少与ps交换数据的通信开销
- emb shards(emb table的子集)分布式存储在多个gpu上(或uvm内存中)(规模不算太大)
- 还可支持动态表,利用ps存储gpu放不下的emb(超大规模)
- ps和uvm的关系
- uvm是在cpu内存中开辟一块空间当作是对gpu显存的扩展,cpu、gpu都能使用同样地指针访问其中的数据,便于开发,但实际上还是会做cpu、gpu间数据的隐式传输
- 使用uvm是在emb table规模不算特别大,但gpu显存无法完全放入所有emb table的情况下使用的,一定程度上扩展显存大小(逻辑大小)
- 而使用超大规模的emb table时,就需要ps存储更多的emb table,再配合动态emb和缓存来实现
- 传统推荐系统的ps架构
- uvm只是对显存一定程度的扩展,便于开发与维护,不能完全解决显存不够用的情况,而实际上还是会发生cpu、gpu间的隐式数据拷贝,甚至使用stream和cudaMemcpyAsync性能会比用uvm更高(参考链接)
- 使用sharder是为了对embedding做模型并行,是为了摆脱以cpu为中心的传统ps架构,提高gpu使用性能,不同的分片方式也是为了解决显存无法存下所有emb table的问题
- 不同的分片方式是考量了不同的系统运行环境以及用户需求,以求最大化性能,个人理解uvm是为分片提供了辅助和简化开发维护,并不是只要用了uvm就能解决显存问题,就不需要模型并行能直接从uvm中读emb做数据并行了,这样反而退化为早期的ps架构,无法充分利用gpu高带宽
EBC&FusedEBC
Embedding 和EmbeddingBag的区别
使用embeddingbag主要是为了解决multi-hot的情况, 而且还能同时支持one-hot
embedding是直接查询出多个emb vec, 而embeddingbag是将查询出的多个emb vec做池化(此处为相加)后输出一个最终的emb vec, 这样就能解决multio-hot的情况(对于一个特征域,不但支持单选,还支持多选)
import torch vocab_size = 5 # feature_slot size embedding_dim = 3 # 大小相同的emb 和emb_bag embedding = nn.Embedding(num_embeddings=vocab_size, embedding_dim=embedding_dim) embedding_bag = nn.EmbeddingBag(num_embeddings=vocab_size, embedding_dim=embedding_dim, mode='sum') >>> embedding.weight Parameter containing: tensor([[ 0.2669, 0.0411, 1.8483], [-0.1264, 0.4678, -0.7871], [-0.9744, -1.1333, -2.0062], [ 0.3138, -1.0656, -0.6442], [ 0.1350, 0.1416, 0.0687]], requires_grad=True) >>> embedding_bag.weight Parameter containing: tensor([[-0.9410, -1.2599, -0.5800], [-1.3137, 0.2207, 0.1835], [ 0.1689, 2.0827, 0.7237], [ 0.2223, -0.5492, -0.6188], [ 0.4136, -1.1578, -0.7838]], requires_grad=True) input_ids = torch.LongTensor([[1, 2, 3]]) >>> embedding(input_ids) tensor([[[-0.1264, 0.4678, -0.7871], [-0.9744, -1.1333, -2.0062], [ 0.3138, -1.0656, -0.6442]]], grad_fn=<EmbeddingBackward0>) >>> embedding_bag(input_ids) tensor([[-0.9225, 1.7543, 0.2883]], grad_fn=<EmbeddingBagBackward0>)
EmbeddingBag和EmbeddingBagCollection的区别
EBC用于管理多个EmbeddingBags
B = 2 D = 8 dense_in_features = 100 eb1_config = EmbeddingBagConfig( name="t1", embedding_dim=D, num_embeddings=100, feature_names=["f1", "f3"] ) eb2_config = EmbeddingBagConfig( name="t2", embedding_dim=D, num_embeddings=100, feature_names=["f2"], ) ebc = EmbeddingBagCollection(tables=[eb1_config, eb2_config]) >>> ebc EmbeddingBagCollection( (embedding_bags): ModuleDict( (t1): EmbeddingBag(100, 8, mode='sum') (t2): EmbeddingBag(100, 8, mode='sum') ) )
EBC和FusedEBC的区别
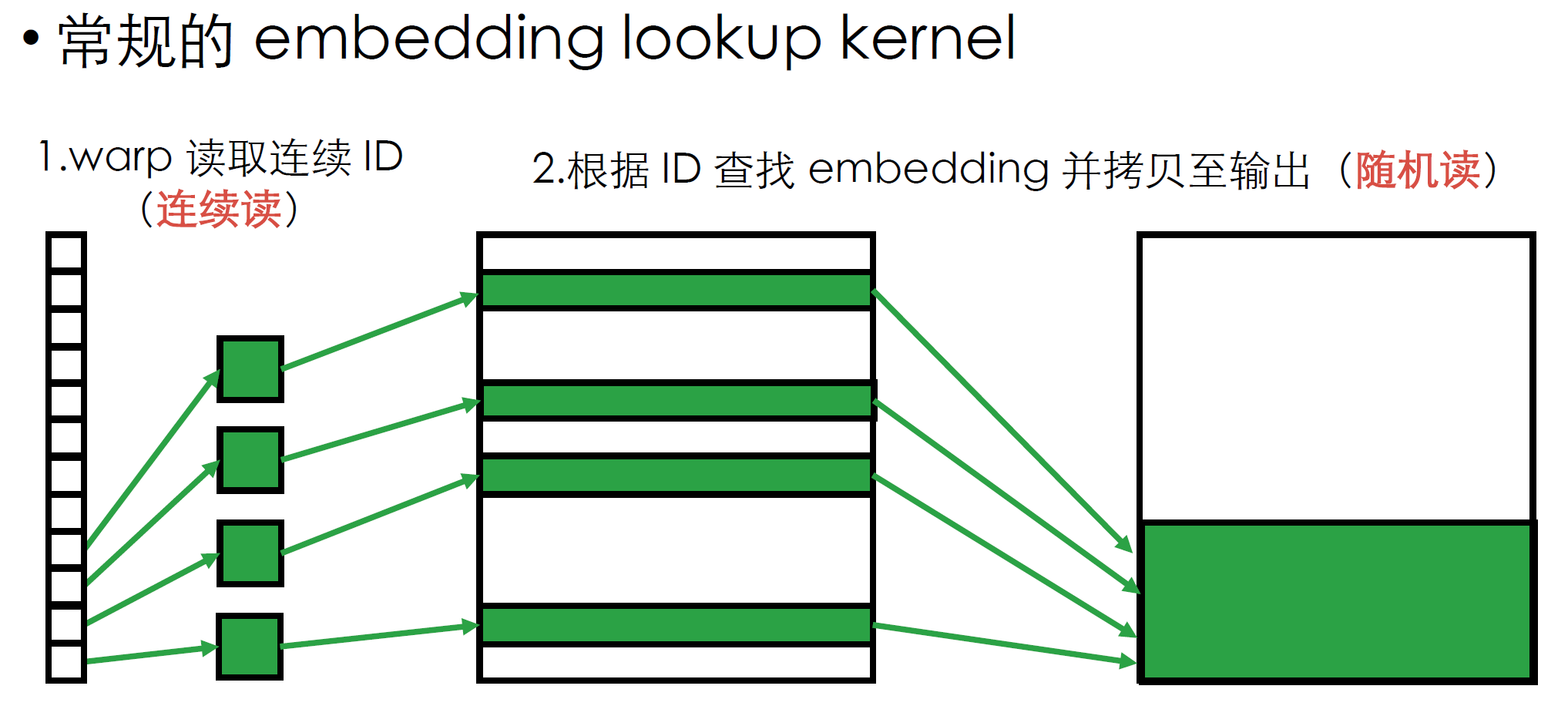
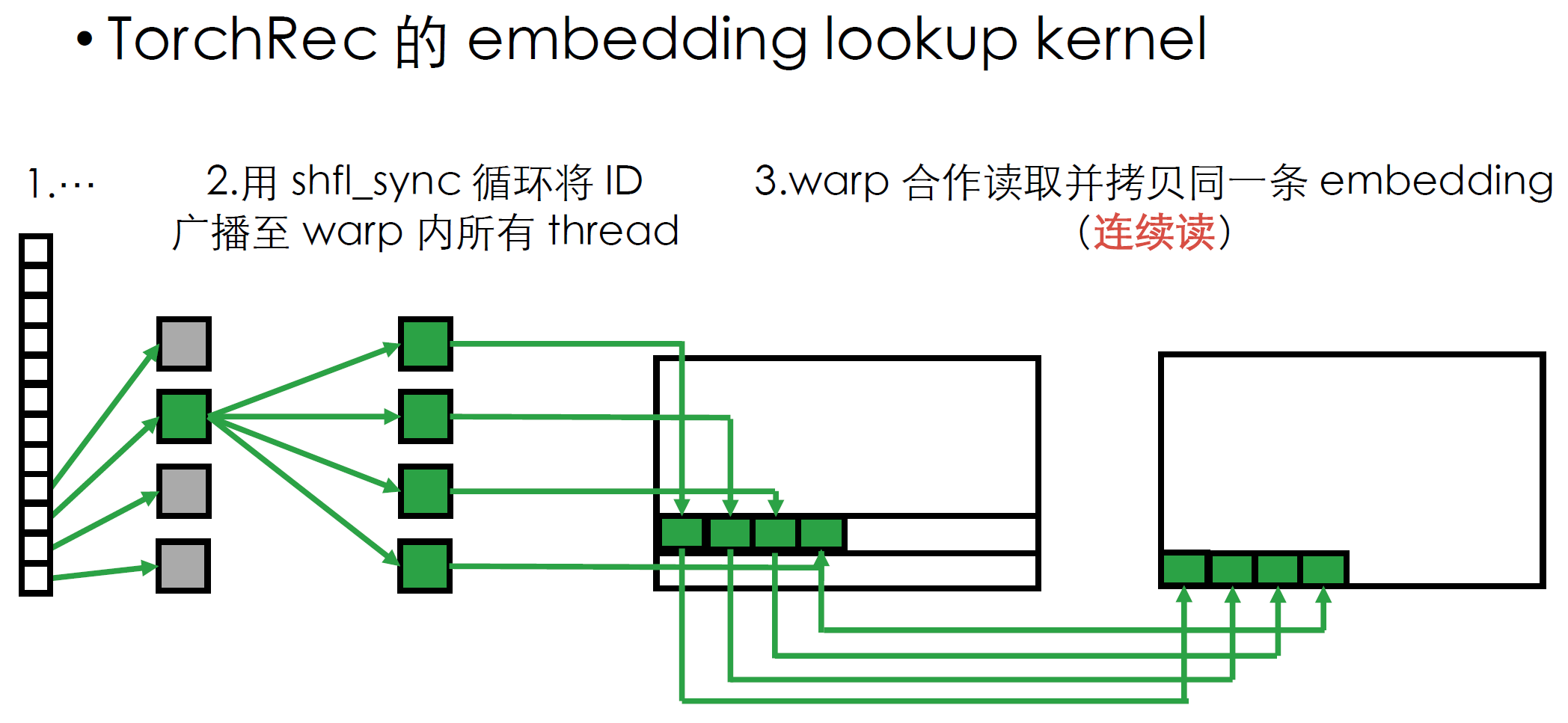
- fused ebc是对普通ebc作了算子方面的融合优化(依赖fbgemm库),如,可使用一个kernel实现多个emb的查询
- 在查表时,常规的方法是一个warp内的所有线程连续读取一组待查询key,再从emb table中随机读取对应emb vector,无法充分利用显存带宽;
- fused ebc的查表方式是使用cuda的shfl_sync,一个warp内的所有thread同时拷贝同一条emb vector,这样两个过程都是连续读
KJT
kjt数据结构是在cpu还是gpu使用?为何会用到不同长度的tensor?
使用不同长度的tensor是为了表示如multi-hot, 缺省值,每个batch中对应特征域特征出现的情况, 在cpu, gpu都会使用
torchrec中是使用EBC结构(基于torch的embeddingbag)存储多个特征域的嵌入表的, 然后使用kjt数据结构作为待查询key的张量, 传入ebc得到对应的嵌入向量
# 示例: #|------------|------------| #| product ID | user ID | #|------------|------------| #| [101, 202] | [404] | #| [] | [505] | #| [303] | [606] | #|------------|------------| mb = torchrec.KeyedJaggedTensor( keys = ["product", "user"], values = torch.tensor([101, 202, 303, 404, 505, 606]).cuda(), lengths = torch.tensor([2, 0, 1, 1, 1, 1], dtype=torch.int64).cuda(), ) print(mb.to(torch.device("cpu"))) >>> KeyedJaggedTensor({ "product": [[101, 202], [], [303]], "user": [[404], [505], [606]] }) # sparse 参数存储 eb1_config = EmbeddingBagConfig( name="t1", embedding_dim=3, num_embeddings=10, feature_names=["f1"] ) eb2_config = EmbeddingBagConfig( name="t2", embedding_dim=3, num_embeddings=12, feature_names=["f2"] ) ebc = EmbeddingBagCollection(tables=[eb1_config]) sparse_arch = SparseArch(ebc) # 0 1 2 <-- batch # 0 [0,1] None [2] # 1 [3] [4] [5,6,7] # feature features = KeyedJaggedTensor.from_offsets_sync( keys=["f1"], values=torch.tensor([0,1,2,3,4,5,6,7]), offsets=torch.tensor([0,2,2,3,4,5,8]), ) >>> sparse_arch(features) tensor([[[-0.0635, -0.6799, -1.8670]], [[ 0.0000, 0.0000, 0.0000]], [[-0.8205, 0.8911, 0.5688]], [[ 1.7768, 0.3763, 0.9286]], [[-1.6304, 1.8683, -0.0427]], [[-1.6682, 2.4401, 0.6767]]], grad_fn=<ReshapeAliasBackward0>)
- embedding分片方式的区别:
- hugectr的distributedslotembeddinghash是将每个slot划分到所有GPU上,相当于torchrec的row-wise sharding
- hugectr的localizedslotembeddinghash是将某个完整的slot分配到某个GPU上,相当于torchrec的table-wise sharding
- 除此之外, torchrec还支持更多的切分方式, 满足用户定制化网络拓扑的需求, 且能够自动选择在当前运行环境下最优的分片方式
- 在分布式上都支持数据模型混合并行, dense网络部分的处理都是数据并行, embedding都是模型并行, 且前向反向的计算过程也都在GPU上进行, 最大程度利用了GPU的并行计算性能
- 在数据加载上也都支持数据读取,分发,训练流水
- 数据预处理:
- torchrec是先补全缺省值,然后重新映射key id到连续id空间,再将出现次数少于阈值3的key映射到key_id=1,再做shuffle
- hugectr也是先补全缺省值,重新映射到连续id, 再将出现次数少于阈值6的key映射到某一特定id,再做shuffle,**最后还可以使用feature cross(特征组合)**进一步减少特征数量,提升组合特征的表达能力
- embedding分片方式的区别:
- 用在模型并行模块中, 为FSDP方式提供支持, 实际上只用在test脚本中, dlrm网络未用到
- 简单总结,就是根据输入网络结构,参数规模, 运行的设备环境的拓扑,设备的带宽,显存, 数据类型等信息, 穷举所有切分方案,然后挑出所有可行的方案做一个模拟性能评估, 根据评估的结果再挑出性能最好的方案出来
- 执行流程&细节:
- 设置Topology, 生成ShardingPlan, Planner有两个阶段:
- Planning stage:在给定sharders和运行环境(Topology)的前提下决定如何切分模型,输出ShardingPlan, 会给出什么切分方式,使用什么compute kernel, perf, rank, 评估将会占用多少HBM存储空间
- Topology类: 代表网络设备集群组织方式, 可设置设备类型, world size, 每个设备的存储空间(hbm,ddr)大小,带宽等.
- Shard: emb的子表, 主要记录了size和offset
- enumerator类用于列举所有可行的方案,之后estimator类再对不同的切分方式做perf /storage estimation, 之后将方案传入proposers按照不同策略对所有方案的评估性能作优劣排序, 最后选择最优的方案
- Sharding stage:根据ShardingPlan使用给定的sharder切分模型,需要在运行环境中执行
- Partitioner, 用于切分shards, 有多种策略,如Greedy, BLDM, Linear等(目前只有Greedy的实现)
- Planning stage:在给定sharders和运行环境(Topology)的前提下决定如何切分模型,输出ShardingPlan, 会给出什么切分方式,使用什么compute kernel, perf, rank, 评估将会占用多少HBM存储空间
- 在rank0上制定plan然后broadcast到所有设备上
- 需要预留出kjt和dense部分的空间出来不考虑在shards占据的空间之内
- 预估embedding wall time perf 和峰值内存,是按照经验设定了一系列如带宽一类的常量来预估的(见constants.py),会计算每一个shards的性能
- 使用ParameterConstaints选择sharding类型提供pooling因子
- 能够帮助planner更准确的评估性能
- 用户设置一些sharding限制项来指导planner, 如,限定什么划分方式, 最少划分多少块, 使用什么计算kernel等
- 超过GPU显存时自动触发UVM Caching
- 设置Topology, 生成ShardingPlan, Planner有两个阶段:
- 使用torch.utils.data.DataLoader从torchrec.datasets.criteo.InMemoryBinaryCriteoIterDataPipe中读取数据, 以torchrec.datasets.utils.Batch数据结构存入用于每个iter
- 没有像hugectr使用keyset list文件直接预先划分好每个pass需要使用什么emb的步骤
torchrec对dlrm网络结构做了对应实现以及优化版本,主要实现了SparseArch, DenseArch, InteractionArch, OverArch, 分别对应网络结构中的Embedding, Bottom MLP, Pairwise interaction, concat&Top MLP
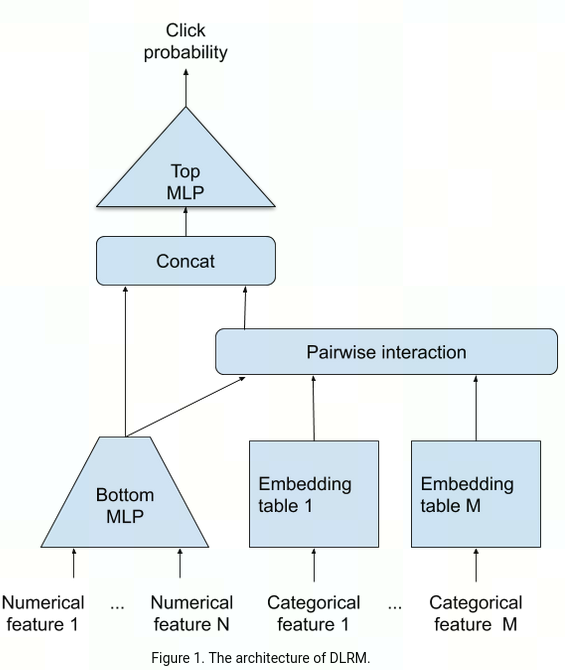
项目中有torchrec对应的网络训练脚本
首先读取网络参数,使用torch.distributed设置好网络拓扑, 后端可选nccl和gloo
rank = int(os.environ["LOCAL_RANK"]) if torch.cuda.is_available(): device: torch.device = torch.device(f"cuda:{rank}") backend = "nccl" torch.cuda.set_device(device) else: device: torch.device = torch.device("cpu") backend = "gloo" if rank == 0: print( "PARAMS: (lr, batch_size, warmup_steps, decay_start, decay_steps): " f"{(args.learning_rate, args.batch_size, args.lr_warmup_steps, args.lr_decay_start, args.lr_decay_steps)}" ) dist.init_process_group(backend=backend)然后设置dataloader,定义模型结构,需要根据使用的数据集定义EBC,定义不同网络层的大小
train_dataloader = get_dataloader(args, backend, "train") val_dataloader = get_dataloader(args, backend, "val") test_dataloader = get_dataloader(args, backend, "test") eb_configs = [ EmbeddingBagConfig( name=f"t_{feature_name}", embedding_dim=args.embedding_dim, num_embeddings=none_throws(args.num_embeddings_per_feature)[feature_idx] if args.num_embeddings is None else args.num_embeddings, feature_names=[feature_name], ) for feature_idx, feature_name in enumerate(DEFAULT_CAT_NAMES) ] sharded_module_kwargs = {} dlrm_model = DLRM( embedding_bag_collection=EmbeddingBagCollection( tables=eb_configs, device=torch.device("meta") ), dense_in_features=len(DEFAULT_INT_NAMES), dense_arch_layer_sizes=args.dense_arch_layer_sizes, over_arch_layer_sizes=args.over_arch_layer_sizes, dense_device=device, ) train_model = DLRMTrain(dlrm_model)指定embedding_optimizer, 使用adagrad或sgd
embedding_optimizer = torch.optim.Adagrad if args.adagrad else torch.optim.SGD apply_optimizer_in_backward( embedding_optimizer, train_model.model.sparse_arch.parameters(), optimizer_kwargs, )定义planner,获取plan
planner = EmbeddingShardingPlanner( topology=Topology( local_world_size=get_local_size(), world_size=dist.get_world_size(), compute_device=device.type, ), batch_size=args.batch_size, # If experience OOM, increase the percentage. see # https://pytorch.org/torchrec/torchrec.distributed.planner.html#torchrec.distributed.planner.storage_reservations.HeuristicalStorageReservation storage_reservation=HeuristicalStorageReservation(percentage=0.05), ) plan = planner.collective_plan( train_model, get_default_sharders(), dist.GroupMember.WORLD )将模型结构、设备、plan传入DMP封装为model
model = DistributedModelParallel( module=train_model, device=device, plan=plan, )指定dense_optimizer后,再与embedding_optimizer合并为最终optimizer
dense_optimizer = KeyedOptimizerWrapper( dict(in_backward_optimizer_filter(model.named_parameters())), optimizer_with_params(), ) optimizer = CombinedOptimizer([model.fused_optimizer, dense_optimizer])定义lr_scheduler
lr_scheduler = LRPolicyScheduler( optimizer, args.lr_warmup_steps, args.lr_decay_start, args.lr_decay_steps )训练
for epoch in range(args.epochs): _train( pipeline, train_dataloader, val_dataloader, epoch, lr_scheduler, args.print_lr, args.validation_freq_within_epoch, args.limit_train_batches, args.limit_val_batches, ) val_auroc = _evaluate(args.limit_val_batches, pipeline, val_dataloader, "val") results.val_aurocs.append(val_auroc) test_auroc = _evaluate(args.limit_test_batches, pipeline, test_dataloader, "test") results.test_auroc = test_auroc按batch读取数据进行训练
def _train( pipeline: TrainPipelineSparseDist, train_dataloader: DataLoader, val_dataloader: DataLoader, epoch: int, lr_scheduler, print_lr: bool, validation_freq: Optional[int], limit_train_batches: Optional[int], limit_val_batches: Optional[int], ) -> None: """ Trains model for 1 epoch. Helper function for train_val_test. Args: pipeline (TrainPipelineSparseDist): data pipeline. train_dataloader (DataLoader): Training set's dataloader. val_dataloader (DataLoader): Validation set's dataloader. epoch (int): The number of complete passes through the training set so far. lr_scheduler (LRPolicyScheduler): Learning rate scheduler. print_lr (bool): Whether to print the learning rate every training step. validation_freq (Optional[int]): The number of training steps between validation runs within an epoch. limit_train_batches (Optional[int]): Limits the training set to the first `limit_train_batches` batches. limit_val_batches (Optional[int]): Limits the validation set to the first `limit_val_batches` batches. Returns: None. """ pipeline._model.train() iterator = itertools.islice(iter(train_dataloader), limit_train_batches) is_rank_zero = dist.get_rank() == 0 if is_rank_zero: pbar = tqdm( iter(int, 1), desc=f"Epoch {epoch}", total=len(train_dataloader), disable=False, ) start_it = 0 n = ( validation_freq if validation_freq else limit_train_batches if limit_train_batches else len(train_dataloader) ) for batched_iterator in batched(iterator, n): for it in itertools.count(start_it): try: if is_rank_zero and print_lr: for i, g in enumerate(pipeline._optimizer.param_groups): print(f"lr: {it} {i} {g['lr']:.6f}") pipeline.progress(batched_iterator) lr_scheduler.step() if is_rank_zero: pbar.update(1) except StopIteration: if is_rank_zero: print("Total number of iterations:", it) start_it = it break if validation_freq and start_it % validation_freq == 0: _evaluate(limit_val_batches, pipeline, val_dataloader, "val") pipeline._model.train()
0.2 迁移计划
- 将collection整合进框架中emb相关部分
- torchrec的dynamic emb并非是真的动态表,只是实现了gpu cache用于存储更大的emb,并不能动态扩增gpu内表大小
- 未支持依赖库解决方法
- 若pytorch组能提供临时版本支持就最好了
- 目前想到的方式是先将高版本pytorch中的对应依赖模块解耦出来放到现在的pytorch1.9版本中重新源码安装
- 或是现实现cpu版本
- 迁移后DLRM网络性能测试、热点分析以及调优
1. 介绍
相关项目:
- https://github.com/pytorch/torchrec
- https://github.com/facebookresearch/dlrm/tree/main/torchrec_dlrm
TorchRec 是PyTorch下大规模推荐系统 (RecSys) 训练框架,能提供推荐系统所需的通用稀疏性和并行性原语,允许使用跨多个 GPU 分片的大型嵌入表来训练模型
- 支持混合数据并行/模型并行,多设备/多节点训练
- https://nvidia-merlin.github.io/HugeCTR/main/hugectr_embedding_training_cache.htmlhttps://nvidia-merlin.github.io/HugeCTR/main/hugectr_embedding_training_cache.htmlhttps://nvidia-merlin.github.io/HugeCTR/main/hugectr_embedding_training_cache.htmlhttps://nvidia-merlin.github.io/HugeCTR/main/hugectr_embedding_training_cache.htmlhttps://nvidia-merlin.github.io/HugeCTR/main/hugectr_embedding_training_cache.htmlhttps://nvidia-merlin.github.io/HugeCTR/main/hugectr_embedding_training_cache.htmlhttps://nvidia-merlin.github.io/HugeCTR/main/hugectr_embedding_training_cache.htmlhttps://nvidia-merlin.github.io/HugeCTR/main/hugectr_embedding_training_cache.html可以使用不同的分片策略对嵌入表进行分片,包括data-parallel, table-wise, row-wise, table-wise-row-wise, 和 column-wise sharding
- TorchRec planner 可以自动为模型生成优化的分片计划
- 支持数据加载(复制到 GPU)、设备间通信和计算(前向、后向)重叠的流水线,以提高性能
- 由 FBGEMM 提供对RecSys的优化kernel,FBGEMM(Facebook 通用矩阵乘法)是用于服务器端推理的低精度、高性能矩阵-矩阵乘法和卷积库
- 支持降低精度的训练推理量化
环境
Python >= 3.7 CUDA >= 11.0 nvcr.io/nvidia/pytorch:23.02-py3 nvcr.io/nvidia/pytorch:22.08-py3依赖库
black cmake fbgemm-gpu-nightly hypothesis iopath numpy pandas pyre-extensions scikit-build tabulate torchmetrics torchx tqdm usort
1.1 安装&测试
# 建议使用pip安装 pip install torchrec_nightly --force-reinstall # 使用源码安装会出现fbgemm-gpu版本问题 pip install -r requirements.txt python setup.py install develop python setup.py --cpu-only install develop # 安装后测试 # torchx run -s local_cwd dist.ddp -j 1x2 --gpu 2 --script test_installation.py # torchrun --nnodes 1 --nproc_per_node 2 --rdzv_backend c10d --rdzv_endpoint localhost --rdzv_id 54321 --role trainer test_installation.py python -m torch.distributed.run --nnodes 1 --nproc_per_node 2 --rdzv_backend c10d --rdzv_endpoint localhost --rdzv_id 54321 --role trainer test_installation.py --cpu_only python -m torch.distributed.launch \ --nproc_per_node 2 \ --nnodes 1 \ --node_rank 0\ --master_addr localhost \ --master_port 54321\ --use-env test_installation.py #dlrm python -m torch.distributed.run --nnodes 1 --nproc_per_node 2 --rdzv_backend c10d --rdzv_endpoint localhost --rdzv_id 54321 --role trainer dlrm_main.py# pytorch安装位置: /torch/venv3/pytorch/lib/python3.7/site-packages/torch # fbgemm安装位置: /torch/venv3/pytorch/lib/python3.7/site-packages/fbgemm_gpu cmake -DCMAKE_PREFIX_PATH=/torch/venv3/pytorch/lib/python3.7/site-packages/torch .. && make -j cmake -DCMAKE_PREFIX_PATH=/opt/conda/lib/python3.8/site-packages/torch .. && make -j # fbgemm源码安装 #cmake -DUSE_SANITIZER=address -DFBGEMM_LIBRARY_TYPE=shared -DPYTHON_EXECUTABLE=/torch/venv3/pytorch/bin/python3 .. #cmake -DUSE_SANITIZER=address -DFBGEMM_LIBRARY_TYPE=shared -DPYTHON_EXECUTABLE=/opt/conda/bin/python3 .. #make -j VERBOSE=1 # fbgemm-gpu源码安装: # 安装conda miniconda_prefix=$HOME/miniconda bash miniconda.sh -b -p "$miniconda_prefix" -u export PATH=$miniconda_prefix/bin:$PATH conda update -n base -c defaults -y conda env_name=fbgemm-install conda create -y --name "${env_name}" python="3.7" source /root/miniconda/etc/profile.d/conda.sh # source /opt/conda/etc/profile.d/conda.sh # conda activate fbgemm_install conda run -n "${env_name}" pip install --upgrade pip conda run -n "${env_name}" python -m pip install pyOpenSSL>22.1.0 conda install -n "${env_name}" -y gxx_linux-64=10.4.0 sysroot_linux-64=2.17 -c conda-forge conda activate fbgemm_install
2. Data Preprocess
criteo-kaggle (7.8GB):
下载与解压数据集
wget http://go.criteo.net/criteo-research-kaggle-display-advertising-challenge-dataset.tar.gz && / tar zxvf criteo-research-kaggle-display-advertising-challenge-dataset.tar.gz预处理数据集(需要70GB内存)
python -m torchrec.datasets.scripts.npy_preproc_criteo --input_dir $INPUT_PATH --output_dir $OUTPUT_PATH --dataset_name criteo_kagglecriteo-1t (655GB):
脚本见项目dlrm https://github.com/facebookresearch/dlrm/blob/main/torchrec_dlrm/scripts/process_Criteo_1TB_Click_Logs_dataset.sh
git clone --recursive https://github.com/facebookresearch/dlrm.git cd ./dlrm/torchrec_dlrm/scripts && \ bash ./process_Criteo_1TB_Click_Logs_dataset.sh /workspace/dataset/favorite/modelzoo-datasets/v1/criteo_terybyte/ /workspace/volume/[your-workspace]/criteo_terabyte/intermediate /workspace/volume/[your-workspace]/criteo_terabyte/output处理方法:
将tsv文件转为npy文件,划分为dense,sparse,label三个npy文件(需要320GB内存)
原始数据类型:每条数据1个label(是否被点击),13个dense特征(int型,多为计数值),26个sparse特征(经hash为32bits数据)
每行数据格式: [label] [integer feature 1] … [integer feature 13] [categorical feature 1] … [categorical feature 26]
torchrec处理dense特征的方式,将整型dense特征转为大于1的float32型
# PyTorch tensors can't handle uint32, but we can save space by not using int64. Numpy will automatically handle dense values >= 2 ** 31. dense_np = np.array(dense, dtype=np.int32) sparse_np = np.array(sparse, dtype=np.int32) labels_np = np.array(labels, dtype=np.int32) # Log is expensive to compute at runtime. dense_np += 3 dense_np = np.log(dense_np, dtype=np.float32) # To be consistent with dense and sparse. labels_np = labels_np.reshape((-1, 1))
将sparse特征处理为contiguous特征(需要480GB内存)
需要所有24天的数据同时输入脚本处理
在所有文件中分别统计每一个特征域出现过的特征的出现频率到sparse_to_frequency中
将出现频率低于frequency_threshold的特征值都映射为1,其余特征值映射为从2开始的连续值(可能出现频率低的特征对最后label的影响小,所以统一处理为1,能够减小特征域大小?)
# Iterate through each row in each file for the current column and remap each # sparse id to a contiguous id. The contiguous ints start at a value of 2 so that # infrequenct IDs (determined by the frequency_threshold) can be remapped to 1. running_sum = 2 sparse_to_contiguous_int: Dict[int, int] = {} for f in file_to_features: print(f"Processing file: {f}") for i, sparse in enumerate(file_to_features[f][col]): if sparse not in sparse_to_contiguous_int: # If the ID appears less than frequency_threshold amount of times # remap the value to 1. if ( frequency_threshold > 1 and sparse_to_frequency[sparse] < frequency_threshold ): sparse_to_contiguous_int[sparse] = 1 else: sparse_to_contiguous_int[sparse] = running_sum running_sum += 1 # Re-map sparse value to contiguous in place. file_to_features[f][col][i] = sparse_to_contiguous_int[sparse]
shuffle(需要700GB内存)
- day0-day22做训练集,shuffle
- day23做验证集,不做shuffle
criteo-multihot (3.5TB):
利用之前处理好的criteo-1t数据集, 合成multi-hot数据集, 用于MLPerf DLRM v2 benchmark (需要200GB内存)
python materialize_synthetic_multihot_dataset.py \ --in_memory_binary_criteo_path $PREPROCESSED_CRITEO_1TB_CLICK_LOGS_DATASET_PATH \ --output_path $MATERIALIZED_DATASET_PATH \ --num_embeddings_per_feature 40000000,39060,17295,7424,20265,3,7122,1543,63,40000000,3067956,405282,10,2209,11938,155,4,976,14,40000000,40000000,40000000,590152,12973,108,36 \ --multi_hot_sizes 3,2,1,2,6,1,1,1,1,7,3,8,1,6,9,5,1,1,1,12,100,27,10,3,1,1 \ --multi_hot_distribution_type uniform
3. Torchrec Benchmarks
benchmark对两种EmbeddingBagCollection模型进行比较
EmbeddingBagCollection(EBC) (code): 由 torch.nn.EmbeddingBag支持FusedEmbeddingBagCollection(Fused EBC) (code): 由FBGEMM kernels 支持,配备了融合优化器和 UVM 或UVM Caching,可为 GPU 提供更大的内存- UVM:
- 能够被CPU或GPU访问的host内存地址空间,使用cudaMalloManaged()分配内存
- 使用UVM能够分配超过显存大小的更多内存,存下更大的嵌入表
- 以page为粒度获取Embedding Table
- UVM caching:
- 以Embedding row为粒度获取embedding
- 使用software managed cache管理,如果GPU miss,则从内存中调用这个row到GPU显存中
- 可设置caching ratio管理缓存大小占整个Embedding Table的比例
- UVM:
run
cd benchmarks # modify ebc_benchmarks.py line14: from torchrec.github.benchmarks import ebc_benchmarks_utils -> import ebc_benchmarks_utils # mode: ebc_comparison_dlrm (default) / fused_ebc_uvm / ebc_comparison_scaling python ebc_benchmarks.py [--mode MODE] [--cpu_only]结论:
- 使用了UVM 或UVM caching的FusedEBC相比EBC模型具有更快的性能表现,且FusedEBC支持超过显存大小的Embedding
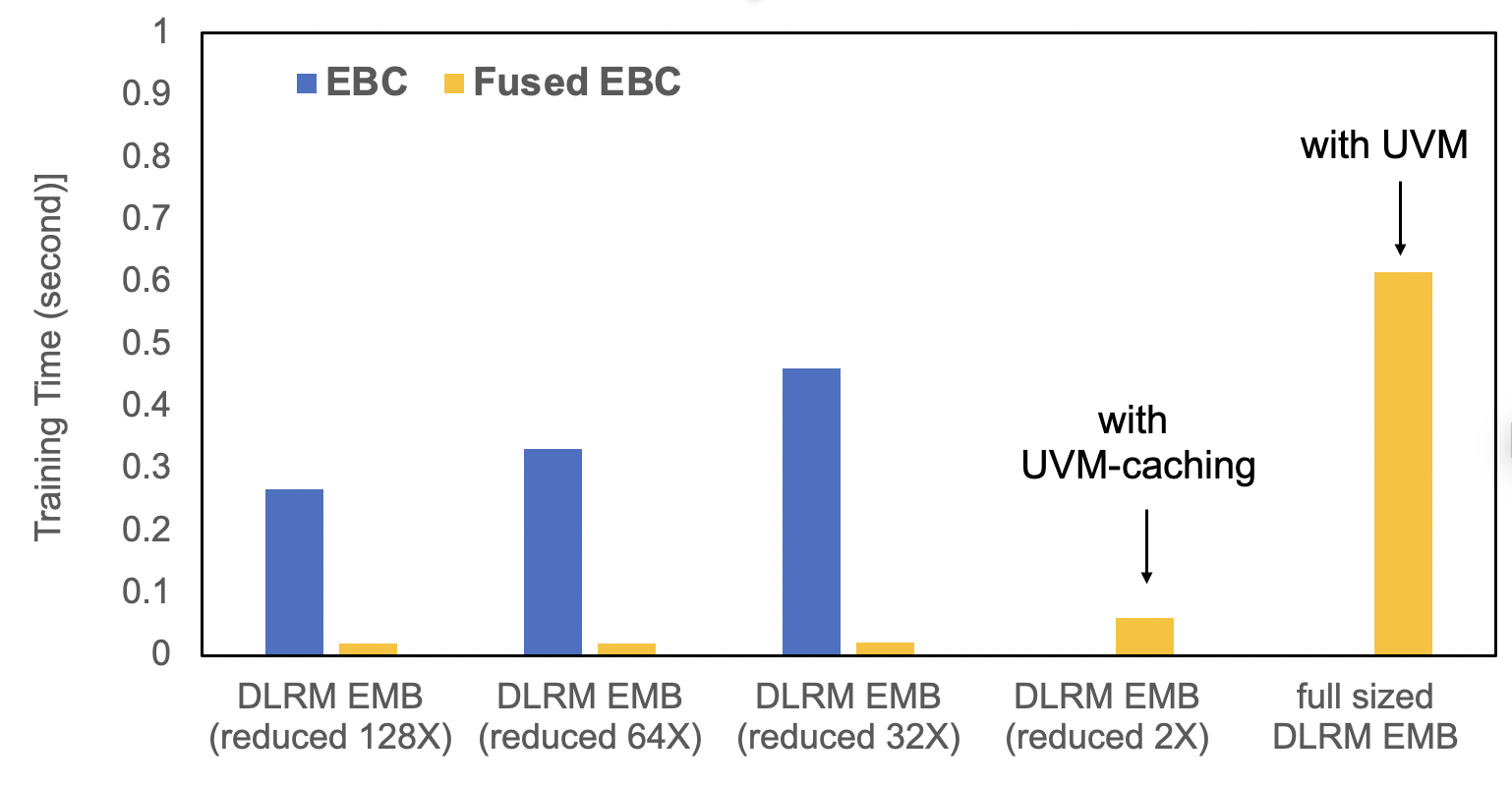
- 使用了UVM 或UVM caching的FusedEBC相比EBC模型具有更快的性能表现,且FusedEBC支持超过显存大小的Embedding
4. DLRM Benchmarks
MLPerf DLRM v1 benchmark
使用DLRM项目下的torchrec_dlrm
git clone --recursive https://github.com/facebookresearch/dlrm.git cd dlrm/torchrec_dlrm预处理数据,处理方法见3小节
run
export PREPROCESSED_DATASET=$insert_your_path_here export TOTAL_TRAINING_SAMPLES=4195197692 ; export GLOBAL_BATCH_SIZE=16384 ; export WORLD_SIZE=8 ; torchx run -s local_cwd dist.ddp -j 1x8 --script dlrm_main.py -- \ --embedding_dim 128 \ --dense_arch_layer_sizes 512,256,128 \ --over_arch_layer_sizes 1024,1024,512,256,1 \ --in_memory_binary_criteo_path $PREPROCESSED_DATASET \ --num_embeddings_per_feature 40000000,39060,17295,7424,20265,3,7122,1543,63,40000000,3067956,405282,10,2209,11938,155,4,976,14,40000000,40000000,40000000,590152,12973,108,36 \ --validation_freq_within_epoch $((TOTAL_TRAINING_SAMPLES / (GLOBAL_BATCH_SIZE * 20))) \ --epochs 1 \ --pin_memory \ --mmap_mode \ --batch_size $((GLOBAL_BATCH_SIZE / WORLD_SIZE)) \ --learning_rate 1.0
MLPerf DLRM v2 benchmark
使用DLRM项目下的torchrec_dlrm
git clone --recursive https://github.com/facebookresearch/dlrm.git cd dlrm/torchrec_dlrm预处理数据,处理方法见3小节
run(使用合成multi-hot数据,3.8TB)
export MULTIHOT_PREPROCESSED_DATASET=$your_path_here export TOTAL_TRAINING_SAMPLES=4195197692 ; export GLOBAL_BATCH_SIZE=65536 ; export WORLD_SIZE=8 ; torchx run -s local_cwd dist.ddp -j 1x8 --script dlrm_main.py -- \ --embedding_dim 128 \ --dense_arch_layer_sizes 512,256,128 \ --over_arch_layer_sizes 1024,1024,512,256,1 \ --synthetic_multi_hot_criteo_path $MULTIHOT_PREPROCESSED_DATASET \ --num_embeddings_per_feature 40000000,39060,17295,7424,20265,3,7122,1543,63,40000000,3067956,405282,10,2209,11938,155,4,976,14,40000000,40000000,40000000,590152,12973,108,36 \ --validation_freq_within_epoch $((TOTAL_TRAINING_SAMPLES / (GLOBAL_BATCH_SIZE * 20))) \ --epochs 1 \ --pin_memory \ --mmap_mode \ --batch_size $((GLOBAL_BATCH_SIZE / WORLD_SIZE)) \ --interaction_type=dcn \ --dcn_num_layers=3 \ --dcn_low_rank_dim=512 \ --adagrad \ --learning_rate 0.005run(使用预处理后的criteo-1t数据集动态生成的multi-hot数据,存储空间不足3.8TB时可用)
export PREPROCESSED_DATASET=$insert_your_path_here export TOTAL_TRAINING_SAMPLES=4195197692 ; export BATCHSIZE=65536 ; export WORLD_SIZE=8 ; torchx run -s local_cwd dist.ddp -j 1x8 --script dlrm_main.py -- \ --embedding_dim 128 \ --dense_arch_layer_sizes 512,256,128 \ --over_arch_layer_sizes 1024,1024,512,256,1 \ --in_memory_binary_criteo_path $PREPROCESSED_DATASET \ --num_embeddings_per_feature 40000000,39060,17295,7424,20265,3,7122,1543,63,40000000,3067956,405282,10,2209,11938,155,4,976,14,40000000,40000000,40000000,590152,12973,108,36 \ --validation_freq_within_epoch $((TOTAL_TRAINING_SAMPLES / (BATCHSIZE * 20))) \ --epochs 1 \ --pin_memory \ --mmap_mode \ --batch_size $((GLOBAL_BATCH_SIZE / WORLD_SIZE)) \ --interaction_type=dcn \ --dcn_num_layers=3 \ --dcn_low_rank_dim=512 \ --adagrad \ --learning_rate 0.005 \ --multi_hot_distribution_type uniform \ --multi_hot_sizes=3,2,1,2,6,1,1,1,1,7,3,8,1,6,9,5,1,1,1,12,100,27,10,3,1,1
MLPerf DLRM Benchmark v1 & v2比较:
DLRM v1 DLRM v2 Optimizer SGD Adagrad Learning Rate 1.0 0.005 Batch size AUC 0.8025 within 1 epoch using 16384 AUC 0.8025 within 1 epoch using 65536 Interaction Layer dot interaction DCN V2 with low rank approximation Dataset Criteo 1TB Click Logs Dataset, but uses a different preprocessing script (repo_root/data_utils.py) Criteo 1TB Click Logs Dataset but the sparse features are replaced with a multi-hot dataset.
使用Criteo Kaggle 数据集, 默认网络参数
使用DLRM项目下的torchrec_dlrm
git clone --recursive https://github.com/facebookresearch/dlrm.git cd dlrm/torchrec_dlrm预处理数据,处理方法见3小节
run
# modify dlrm/torchrec_dlrm/data/dlrm_dataloader.py line87: # (root_name, stage) = ("train", "test") if stage == "val" else stage # -> (root_name, stage) = ("train", "test") if stage == "val" else (stage, stage) export PREPROCESSED_DATASET="/workspace/volume/torchrec-criteo-datasets/criteo-kaggle" export GLOBAL_BATCH_SIZE=16384 ; export WORLD_SIZE=8 ; torchx run -s local_cwd dist.ddp -j 1x8 --script dlrm_main.py -- \ --in_memory_binary_criteo_path $PREPROCESSED_DATASET \ --pin_memory \ --mmap_mode \ --batch_size $((GLOBAL_BATCH_SIZE / WORLD_SIZE)) \ --learning_rate 1.0 \ --dataset_name criteo_kaggle
6. DLRM Benchmarks测试结果
测试环境:
distributed-training/torchrec:pytorch22.08-py3 8*A100-SXM4-80GB MLPerf DLRM v1 benchmark, 1 epoch
- AUROC over val set: 0.8004854917526245
- AUROC over test set: 0.7949966788291931
MLPerf DLRM v2 benchmark, 1 epoch
- AUROC over val set: 0.8040649890899658
- AUROC over test set: 0.7980538010597229
使用Criteo Kaggle 数据集, 默认网络参数, 1 epoch
AUROC over val set: 0.5002527236938477
torchrec-dlrm项目原来不支持criteo-kaggle数据集,今年2月增加支持
因为criteo-kaggle数据集没有验证集,只能从训练集中划分一部分做验证集
原代码加载数据集时报错:
File "./dlrm/torchrec_dlrm/data/dlrm_dataloader.py", line 87, in _get_in_memory_dataloader dlrm_main/0 [2]: (root_name, stage) = ("train", "test") if stage == "val" else stage dlrm_main/0 [3]:ValueError: too many values to unpack (expected 2)将(root_name, stage) = ("train", "test") if stage == "val" else stage,修改为(root_name, stage) = ("train", "test") if stage == "val" else (stage, stage)后可跑通,但验证时AUROC只有0.5002527236938477,且修改超参仍无法提升
7. Torchrec与HugeCTR比较
Torchrec:
- 架构,特点,优缺点:
- 优点:
- 实现分布式模型并行,支持数据模型混合并行,多种emb切分方式
- 可根据设备型号与数量,内存大小等信息自动生成切分策略:根据输入网络结构,参数规模, 运行的设备环境的拓扑,设备的带宽,显存, 数据类型等信息, 穷举所有切分方案,然后挑出所有可行的方案做一个模拟性能评估, 根据评估的结果再挑出性能最好的方案出来
- 支持多级流水,重叠数据加载,设备间通信(数据分发)和前反向优化计算
- fbgemm库优化kernel,量化等
- PS架构,CPU做Server,GPU做Workers
- 传统PS架构emb在CPU上,需要将更新特征推送回ps,需等待通信,难以组成流水,无法充分利用算力
- 当前架构利用gpu高带宽交换emb,减少通信开销,且充分利用并行计算性能
- 支持GPU cache机制,存储热数据,使用LRU或LFU混合驱逐策略,使用32位数据结构记录数据使用情况:低27位记录时间戳,高5位记录出现频次(概率算法,每次取频次位随机数,全0加一),LFU比LRU优先级高
- 支持onehot和multihot以及缺省值数据,更符合真实场景
- 缺点:
- 支持功能多,导致框架内部中间数据传递低效,需多次转换
- 不支持动态扩表,只支持静态表,无法处理新特征
- 新网络适配到框架需要做一定开发,无法直接使用封装接口
- 优点:
- 数据流:
- 大多实际业务数据是TB级的,可分为onehot和multihot数据,相当于某一选项单选还是多选
- criteo-1t点击率数据集:1label-13dense(数值型)-26-sparse(分类型),共24天数据,大小达655GB
- 数据预处理:
- 将dense int32转为float32(求log),划分为三个npy文件
- 将sparse特征连续化,统计所有出现的特征数量,低于某一阈值的特征都映射为key=1,其余依次累计key值
- 0-22天的数据做训练集,shuffle,23天做验证集,不shuffle
- 数据并行-模型并行-数据并行:
- 数据在内存中通过DDP均匀分发到不同设备上(每张卡数据不同)【scatter】
- 不同卡拿到训练数据需要到对应emb表中查询vector,每章表根据plan存储在不同设备上【all2all】
- 拿到emb数据后再传入后续网络结构中训练,每个设备上的dense 网络部分需要同步【allreduce】
- 最后经过反向梯度传到每个设备上的emb表中,再更新表的权值
- 测试结果:8A100 SXM4 80G
- MLPerf DLRM v1: 0.8004
- MLPerf DLRM v2: 0.8041
- 迁移方案&遇到的问题与解决方法:
- 使用设备端哈希表存储emb,来实现动态扩容
- key和value分别存储到两张表,key映射到value,key表扩容开辟一块新空间,拷贝到新表,value以链表形式存储,直接追加到表尾
- 版本与依赖库问题:原生框架只支持pt1.13以上,需要切分和fbgemm库提供支持,因此需要替换或避免这些功能
- 将使用到fbgemm库的位置替换实现或重写,使用cnco
- 将使用到高版本pt的模块解耦出来作为子模块使用
- 不同语言实现的模块使用torch_library绑定c++接口到py端
- auroc使用sklearn替换实现,使用集合通信接口将数据传回cpu做计算
- 使用设备端哈希表存储emb,来实现动态扩容
- 性能提升:
- 使用profiler获取host和device侧算子和kernel调用情况,找出热点算子,再提issue或替换算子来提升精度
- 因为不再使用fbgemm库,部分框架功能实现性能差,如内部数据间的相互转换使用低效的标量操作,替换为矩阵操作快很多
- 精度提升:
- 不同语言间实现的模块在配合使用时用到了不同的stream,传参时没能同步,会导致数据异常
- 数据初始化方式使用与表大小相关的均匀分布,精度会更高
- 架构,特点,优缺点:
HugeCTR:
- 架构,特点,优缺点,异同:
- 相同:都支持读取分发训练流水
- 不同:
- hugectr只支持按行按表切分emb,torchrec能自动选择且能混合多种切分方式
- 两者数据预处理方式相似,只是hugectr还可使用特征组合进一步减少特征数量,提升表达能力
- hugectr使用keylist预先划分好训练数据,torchrec直接使用dataloader读取
- hctr支持动态表,使用GPU上的hashtable实现(cucollection)
- hugectr更加完善,是merlin推荐系统模型推理训练解决方案下的训练框架,支持GPU中的hash表,异步与多线程流水,分层参数服务器做推理,TF插件sok
- 训练时,hugectr预取每个pass的key集合到keyset,从而解决无法存放所有数据的难题
- 参数服务器支持全量读如整个emb到host内存中(速度快),或使用多级缓存结构只存部分(克服对模型规模的限制)
- 推理时,三级存储结构:使用GPU嵌入缓存将热点emb放在gpu内存中,内存作为二级,使用redis保存部分数据;第三级使用SSD RocksDB保存所有参数(高效存储长尾分布数据),使用的是LRU
- 架构,特点,优缺点,异同:
Relevant:
- GPU hashtable:
- hash冲突处理方法:
- double hash,分别计算再聚合
- frequency hash:对低频做双hash,高频做identity hash
- hash冲突处理方法:
- 性能指标:profiling timechart, 吞吐量
- 精度指标:AUC
- GPU hashtable: